Normalize intensities across batches
Joyce Hsiao
Last updated: 2018-02-14
Code version: 81b6e41
Introduction/summary
The experimental design for our study is commonly known as “incomplete block design”. The individuals are grouped into combinations of two, and no two individuals appear in the same combination twice. In our study, combination refers to C1 plates, so the combination of cell lines on each C1 plate is thereofre unique.
In notations,
\(N\): number of individuals \(k\): combination size (in our case, each combinatino is a plate) \(B\): number of plates \(r_i\): number of replicates for individual \(i\) in the entire design
For now assume \(r_i=r\) for all individuals. Then, in our design each individual replicate can pair up with \(N-1/k-1\) possible number of individuals. And since the pairs consist of unique individuals, so there can be \(N-1/k-1\) possible number of replicates for each individual. We have \(N=6, k=2\) which gives 5 replicates per individual cell line.
Our design is in principle balanced, i.e., each pair of individuals occurs together one time in the study. But at the end of the experiment, we collected an additional C1 plate on the first pair of individuals processed. This gives us a total of 16 plates (pairs or blocks).
I performed analysis of variance for intensity data using the following model
\[ y_{ij} = \mu + \tau_i + \beta_j + \epsilon_{ij} \] where \(i = 1,2,..., N\) and \(j = 1,2,..., B\). The parameters are estimated under sum-to-zero constraints \(\sum \tau_i = 0\) and \(\sum \beta_j = 0\).
Note that in this model 1) not all \(y_{ij}\) exists due to the incompleteness of the design, 2) the effects of individual and block are nonorthogonal, 3) the effects are additive due to the block design.
We implemented the above model using the ibd package and
Estimate prop of variance explained by individual and plate.
Estimate mean effect from each plate, correct from the intensity data
TO DO: Apply batch correction prior to background correction??
Load data
\(~\)
library(data.table)
library(dplyr)
library(ggplot2)
library(cowplot)
library(wesanderson)
library(RColorBrewer)
library(Biobase)
library(scales)
# note that ibd is not in the fucci-seq conda environment
library(ibd)Read in filtered data.
df <- readRDS(file="../data/eset-filtered.rds")
pdata <- pData(df)
fdata <- fData(df)RFP variation
RFP
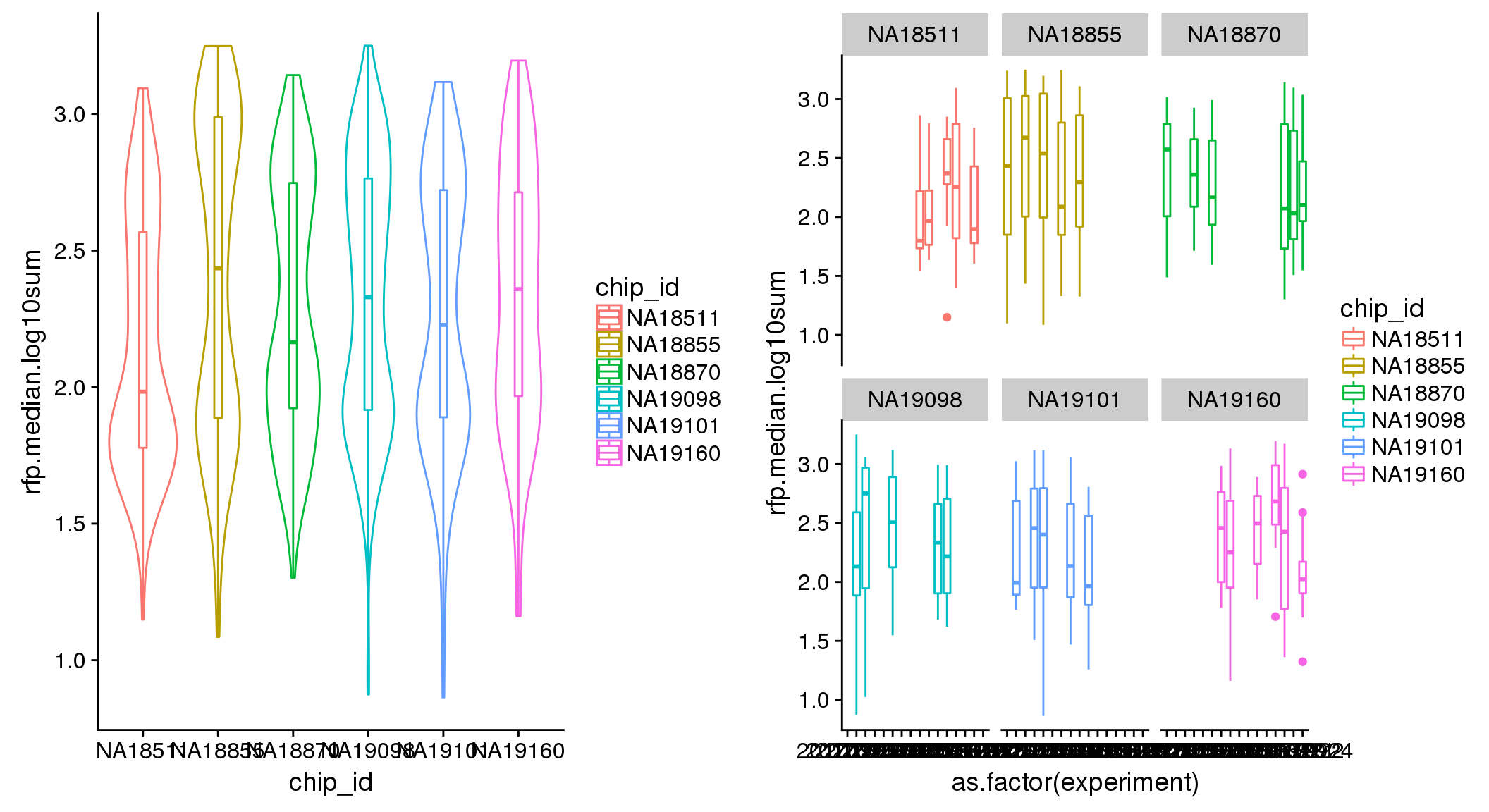
ANOVA: No signficant variation due to individual cell lines of origin (p<.01), but signification variation due to experiment. Based on the contrast tests for the plate effect, “20170907” and “20170924” are the two plates that differ the most from the others. Based on the contrast tests for the individual effect, “NA18511” differs the most from the average sample intensities.
ibd_rfp <- aov.ibd(rfp.median.log10sum~factor(chip_id)+factor(experiment),data=pdata)
# make contrast matrix for plates
# each plate is compared to the average
n_plates <- uniqueN(pdata$experiment)
contrast_plates <- matrix(-1, nrow=n_plates, ncol=n_plates)
diag(contrast_plates) <- n_plates-1
ibd_rfp_exp <- aov.ibd(rfp.median.log10sum~factor(chip_id)+factor(experiment),
data=pdata, spec="experiment", contrast=contrast_plates)
ibd_rfp_exp_est <- ibd_rfp_exp$LSMEANS
# make contrast matrix for individuals
# each individual is compared to the average
n_inds <- uniqueN(pdata$chip_id)
contrast_inds <- matrix(-1, nrow=n_inds, ncol=n_inds)
diag(contrast_inds) <- n_inds-1
ibd_rfp_chipid <- aov.ibd(rfp.median.log10sum~factor(chip_id)+factor(experiment),
data=pdata, spec="chip_id", contrast=contrast_inds)Substract plate effect from the raw estimates.
pdata$rfp.median.log10sum.adjust <- pdata$rfp.median.log10sum
ibd_rfp_exp_est$experiment <- as.character(ibd_rfp_exp_est$experiment)
pdata$experiment <- as.character(pdata$experiment)
exps <- unique(pdata$experiment)
for (i in 1:uniqueN(exps)) {
exp <- exps[i]
ii_exp <- which(pdata$experiment == exp)
est_exp <- ibd_rfp_exp_est$lsmean[which(ibd_rfp_exp_est$experiment==exp)]
pdata$rfp.median.log10sum.adjust[ii_exp] <- (pdata$rfp.median.log10sum[ii_exp] - est_exp)
}
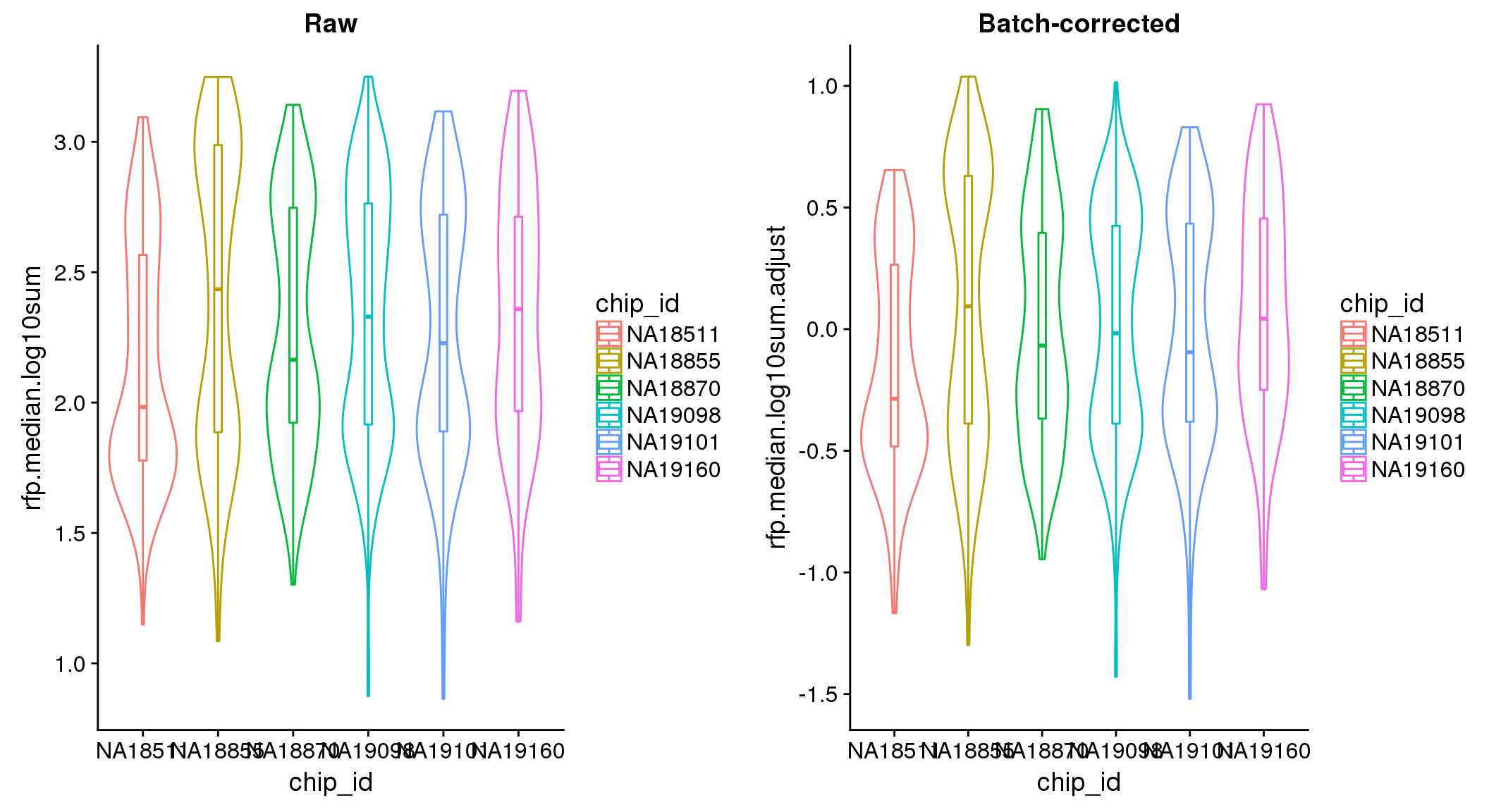
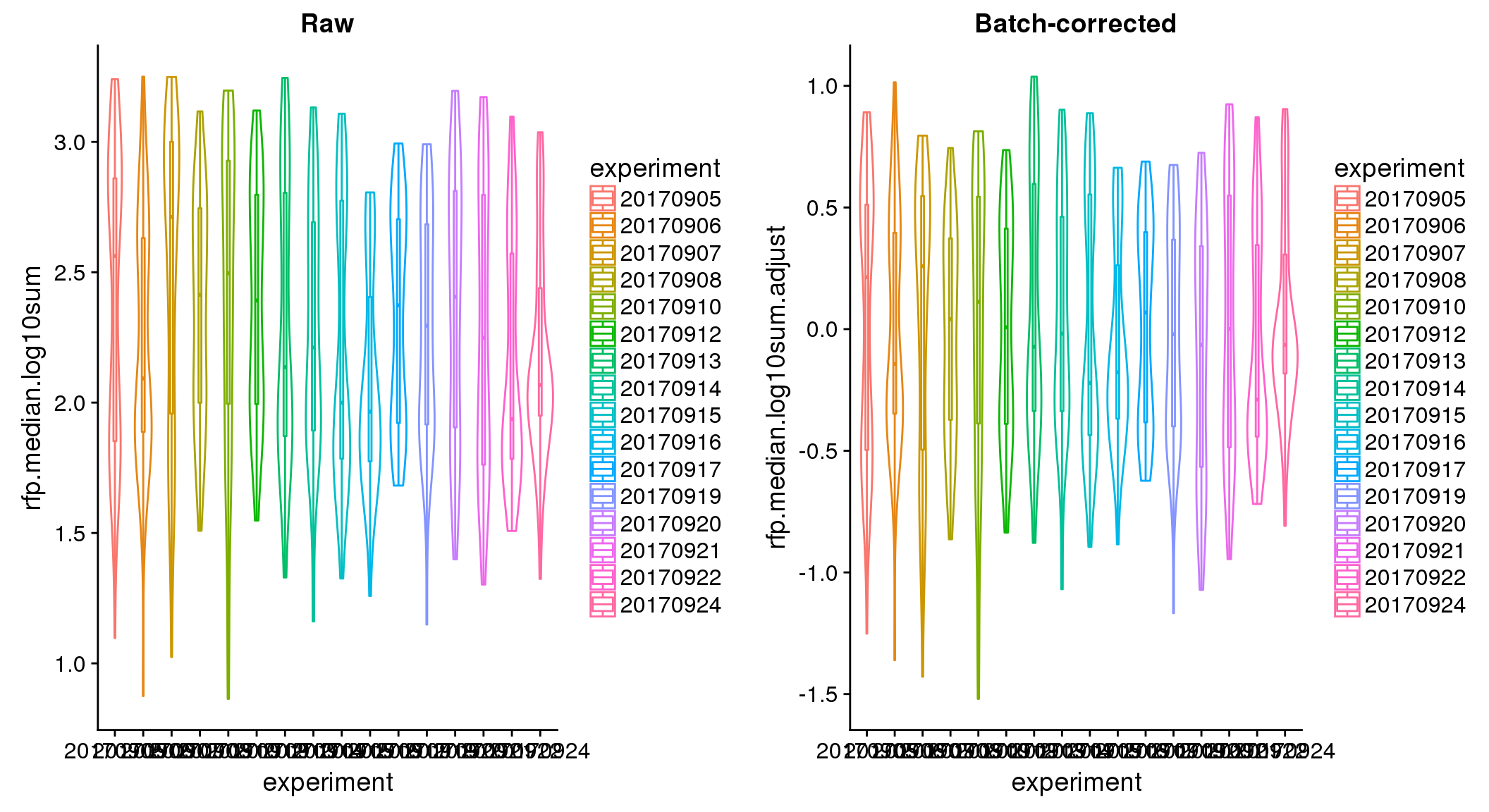
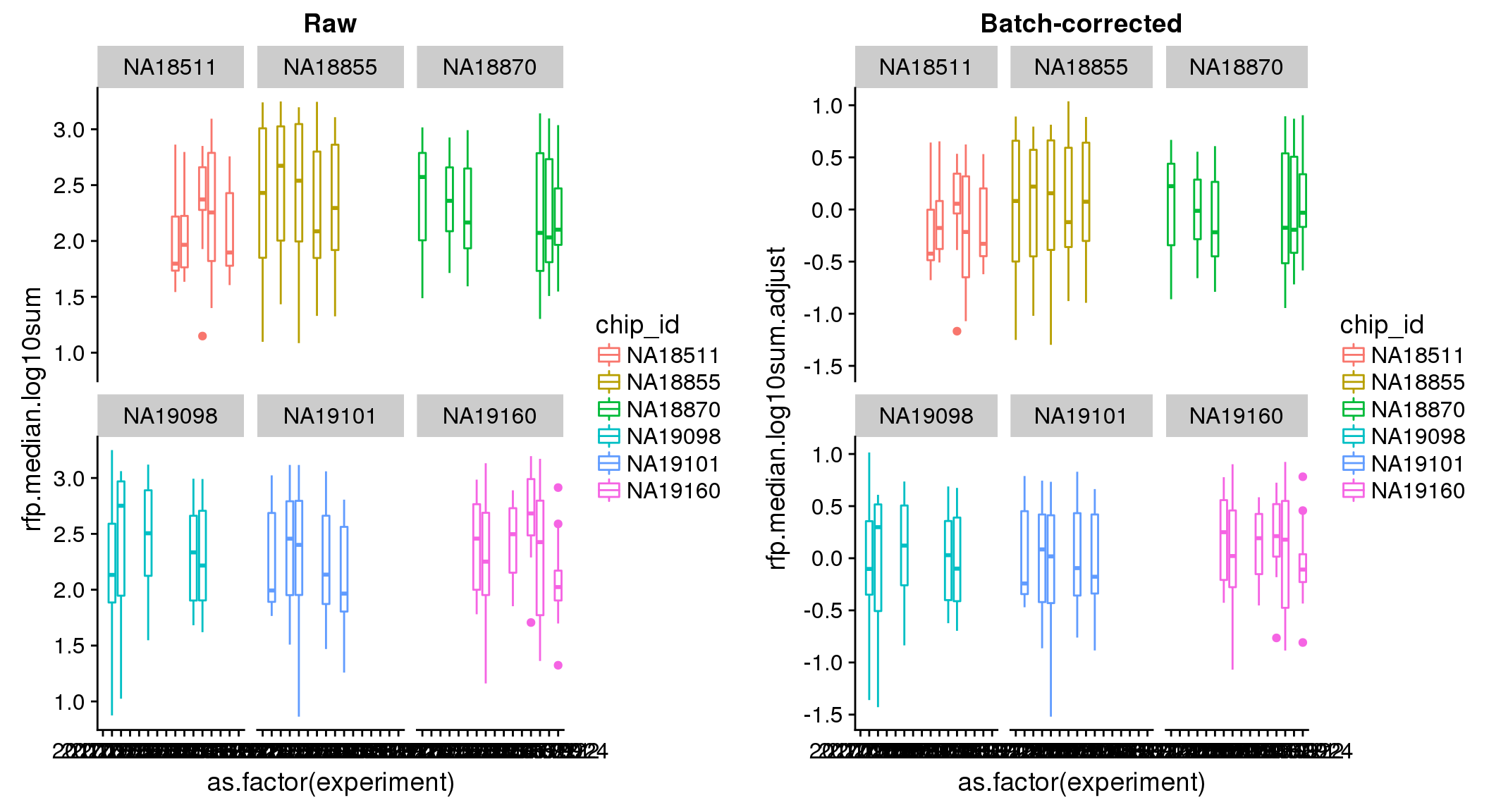
ANOVA on adjusted data show no significant batch/block effect.
aov.ibd(rfp.median.log10sum.adjust~factor(chip_id)+factor(experiment),data=pdata)$ANOVA.table
Anova Table (Type III tests)
Response: rfp.median.log10sum.adjust
Sum Sq Df F value Pr(>F)
(Intercept) 0.766 1 3.2144 0.07331 .
factor(chip_id) 3.273 5 2.7469 0.01792 *
factor(experiment) 0.000 15 0.0000 1.00000
Residuals 230.886 969
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1GFP variation
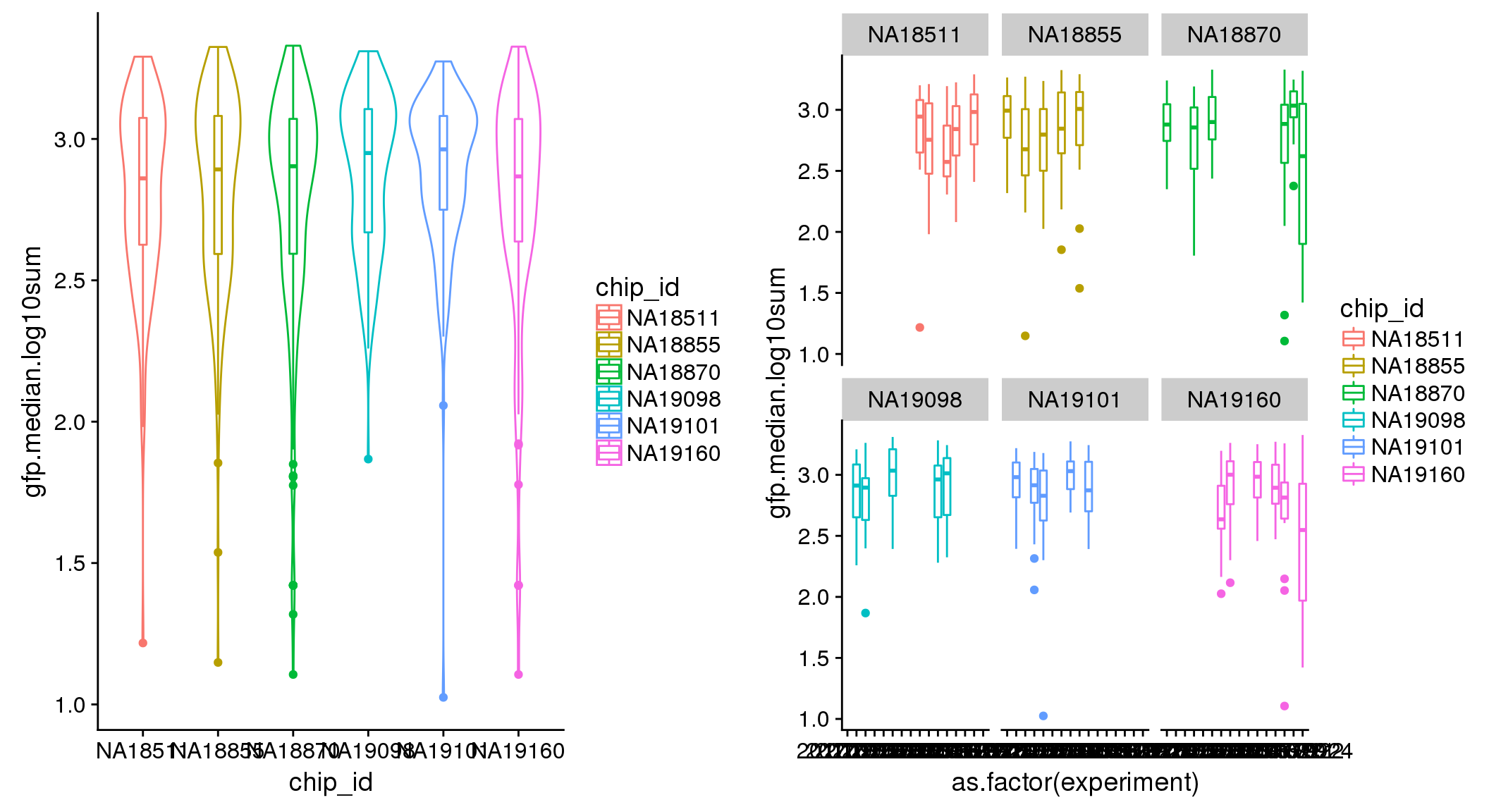
ANOVA: No signficant variation due to individual cell lines of origin (p<.01), but signification variation due to experiment. Based on the contrast tests for the plate effect, “20170907” “20170912” “20170922” “20170924” are the two plates that differ the most from the others. Based on the contrast tests for the individual effect, “NA18511” differs the most from the average sample intensities.
ibd_gfp <- aov.ibd(gfp.median.log10sum~factor(chip_id)+factor(experiment),data=pdata)
# make contrast matrix
n_plates <- uniqueN(pdata$experiment)
contrast_plates <- matrix(-1, nrow=n_plates, ncol=n_plates)
diag(contrast_plates) <- n_plates-1
ibd_gfp_exp <- aov.ibd(gfp.median.log10sum~factor(chip_id)+factor(experiment),
data=pdata, spec="experiment", contrast=contrast_plates)
ibd_gfp_exp_est <- ibd_gfp_exp$LSMEANS
n_inds <- uniqueN(pdata$chip_id)
contrast_inds <- matrix(-1, nrow=n_inds, ncol=n_inds)
diag(contrast_inds) <- n_inds-1
ibd_gfp_chipid <- aov.ibd(gfp.median.log10sum~factor(chip_id)+factor(experiment),
data=pdata, spec="chip_id", contrast=contrast_inds)Substract plate effect from the raw estimates.
pdata$gfp.median.log10sum.adjust <- pdata$gfp.median.log10sum
ibd_gfp_exp_est$experiment <- as.character(ibd_gfp_exp_est$experiment)
pdata$experiment <- as.character(pdata$experiment)
exps <- unique(pdata$experiment)
for (i in 1:uniqueN(exps)) {
exp <- exps[i]
ii_exp <- which(pdata$experiment == exp)
est_exp <- ibd_gfp_exp_est$lsmean[which(ibd_gfp_exp_est$experiment==exp)]
pdata$gfp.median.log10sum.adjust[ii_exp] <- (pdata$gfp.median.log10sum[ii_exp] - est_exp)
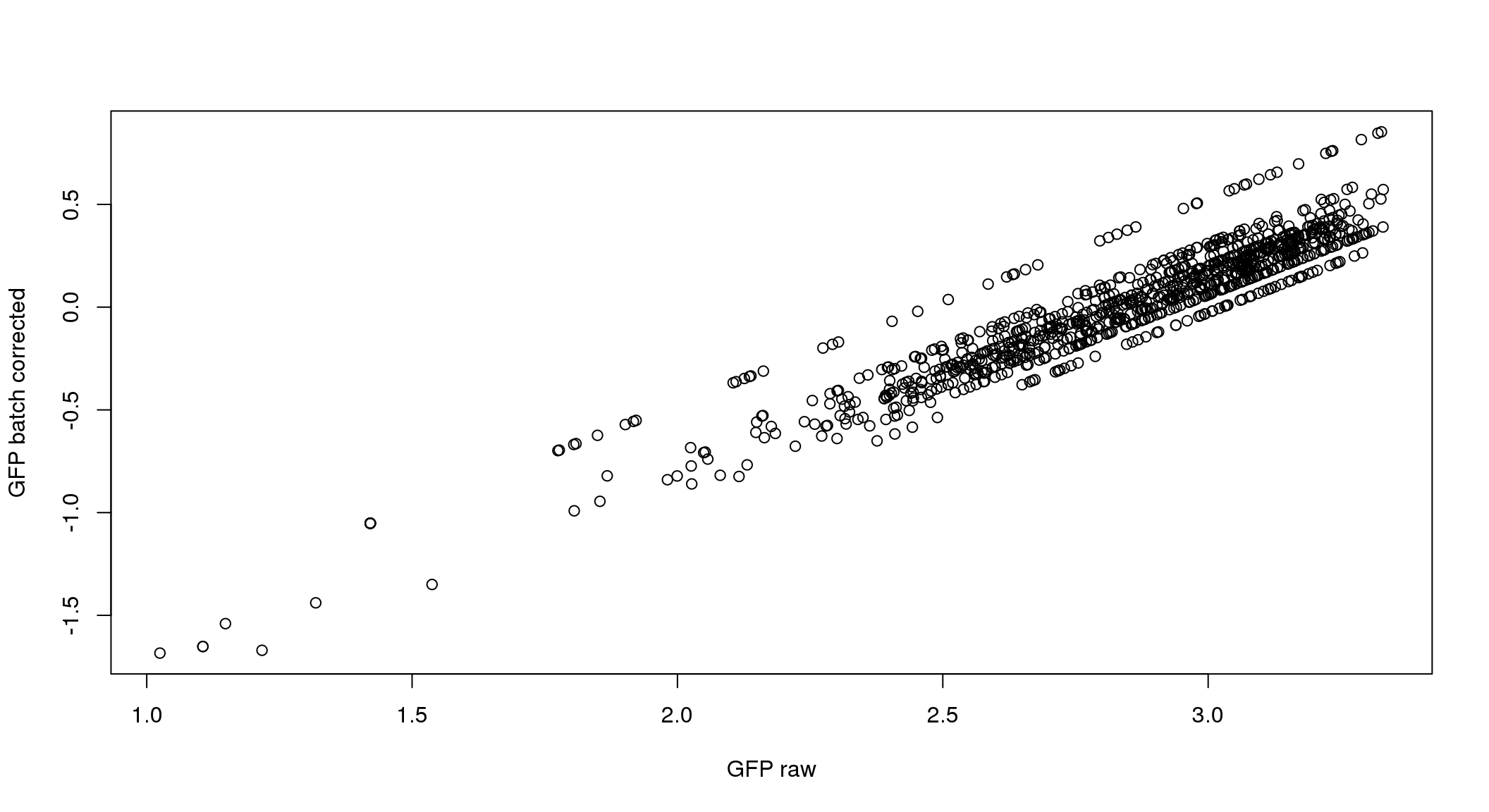
}
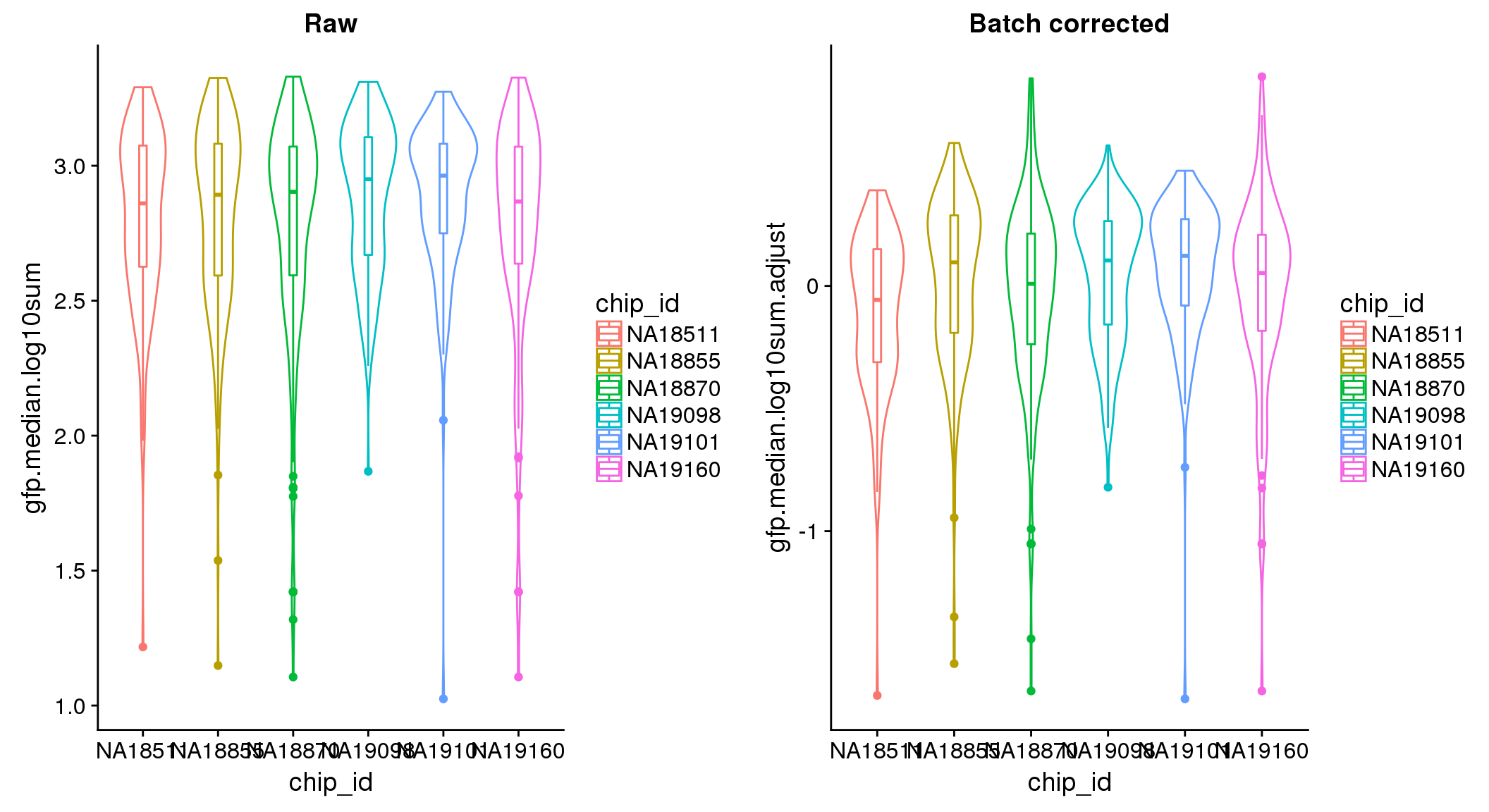
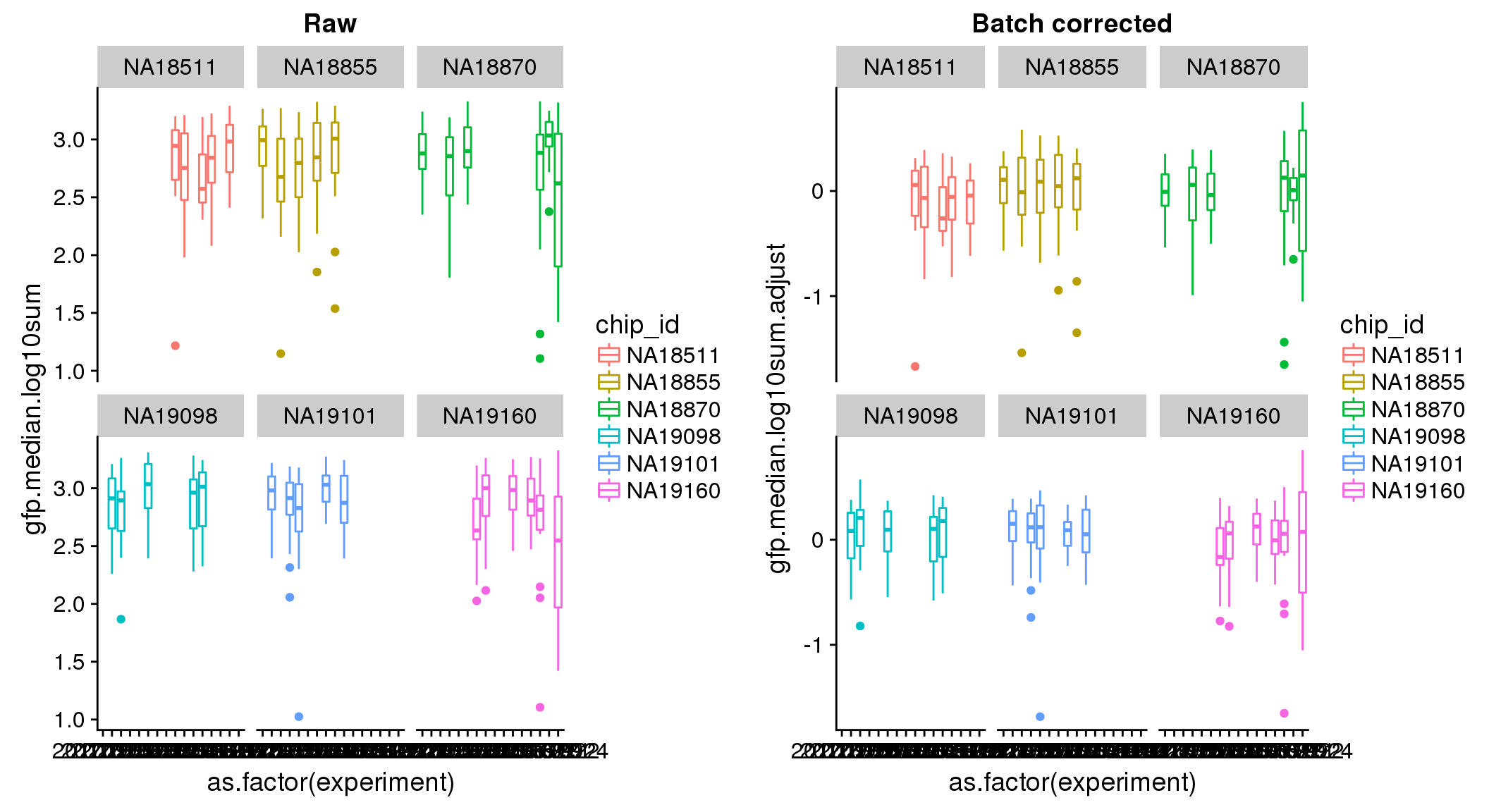
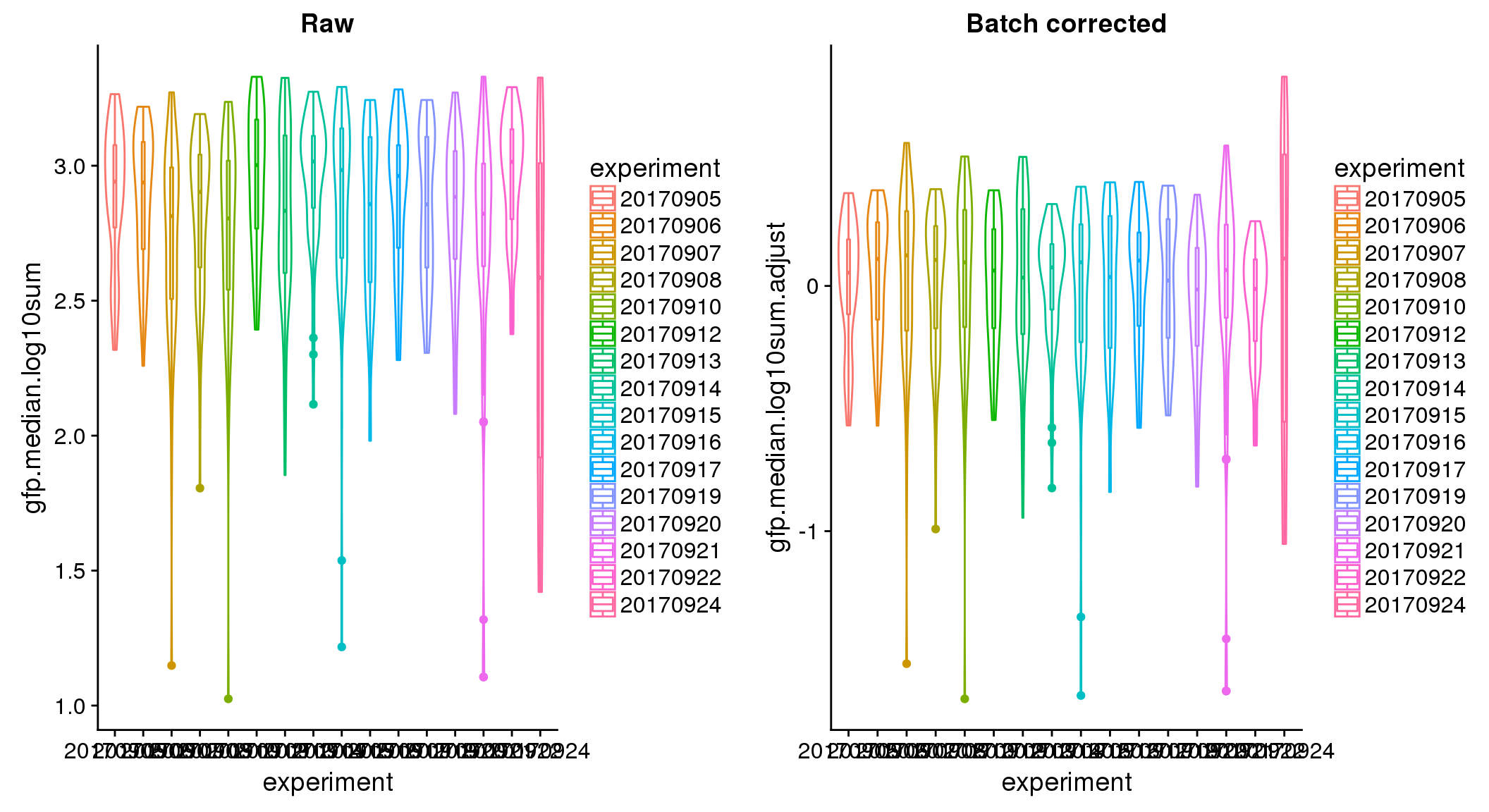
ANOVA on corrected data showed no significant plate effect.
aov.ibd(gfp.median.log10sum.adjust~factor(chip_id)+factor(experiment),data=pdata)$ANOVA.table
Anova Table (Type III tests)
Response: gfp.median.log10sum.adjust
Sum Sq Df F value Pr(>F)
(Intercept) 0.317 1 2.8763 0.09022 .
factor(chip_id) 1.419 5 2.5737 0.02529 *
factor(experiment) 0.000 15 0.0000 1.00000
Residuals 106.879 969
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1DAPI variation
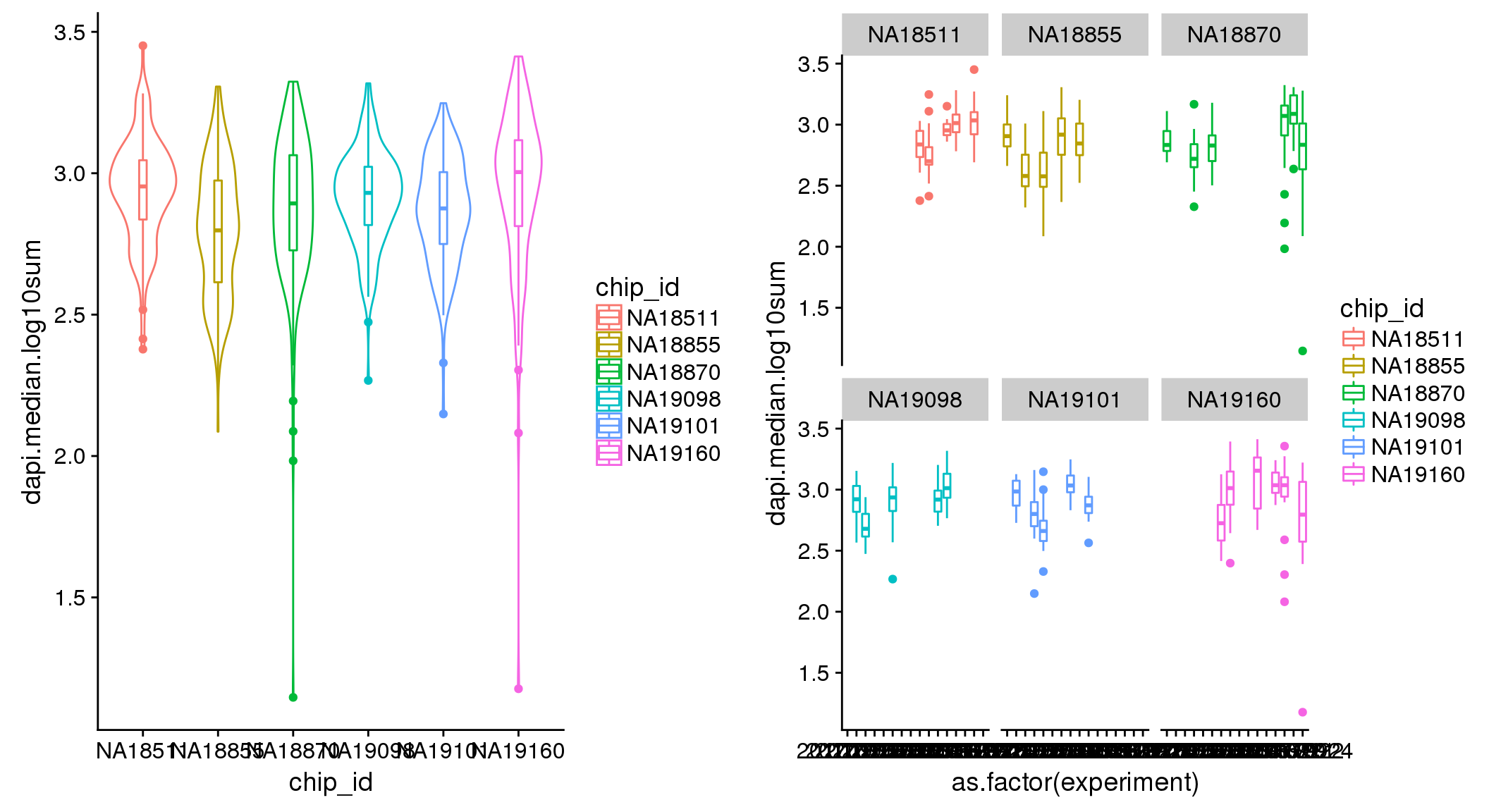
ANOVA: No signficant variation due to individual cell lines of origin (p<.01), but signification variation due to experiment. Based on the contrast tests for the plate effect, the plates are quite different from each other and there are 9 plates that differ from the average (“20170907” “20170908” “20170910” “20170914” “20170919” “20170920” “20170921” “20170922” “20170924”). Based on the contrast tests for the individual effect, “NA19101” differs the most from the average sample intensities.
ibd_dapi <- aov.ibd(dapi.median.log10sum~factor(chip_id)+factor(experiment),data=pdata)
# make contrast matrix
n_plates <- uniqueN(pdata$experiment)
contrast_plates <- matrix(-1, nrow=n_plates, ncol=n_plates)
diag(contrast_plates) <- n_plates-1
ibd_dapi_exp <- aov.ibd(dapi.median.log10sum~factor(chip_id)+factor(experiment),
data=pdata, spec="experiment", contrast=contrast_plates)
ibd_dapi_exp_est <- ibd_dapi_exp$LSMEANS
n_inds <- uniqueN(pdata$chip_id)
contrast_inds <- matrix(-1, nrow=n_inds, ncol=n_inds)
diag(contrast_inds) <- n_inds-1
ibd_dapi_chipid <- aov.ibd(dapi.median.log10sum~factor(chip_id)+factor(experiment),
data=pdata, spec="chip_id", contrast=contrast_inds)Substract plate effect from the raw estimates.
pdata$dapi.median.log10sum.adjust <- pdata$dapi.median.log10sum
ibd_dapi_exp_est$experiment <- as.character(ibd_dapi_exp_est$experiment)
pdata$experiment <- as.character(pdata$experiment)
exps <- unique(pdata$experiment)
for (i in 1:uniqueN(exps)) {
exp <- exps[i]
ii_exp <- which(pdata$experiment == exp)
est_exp <- ibd_dapi_exp_est$lsmean[which(ibd_dapi_exp_est$experiment==exp)]
pdata$dapi.median.log10sum.adjust[ii_exp] <- (pdata$dapi.median.log10sum[ii_exp] - est_exp)
}
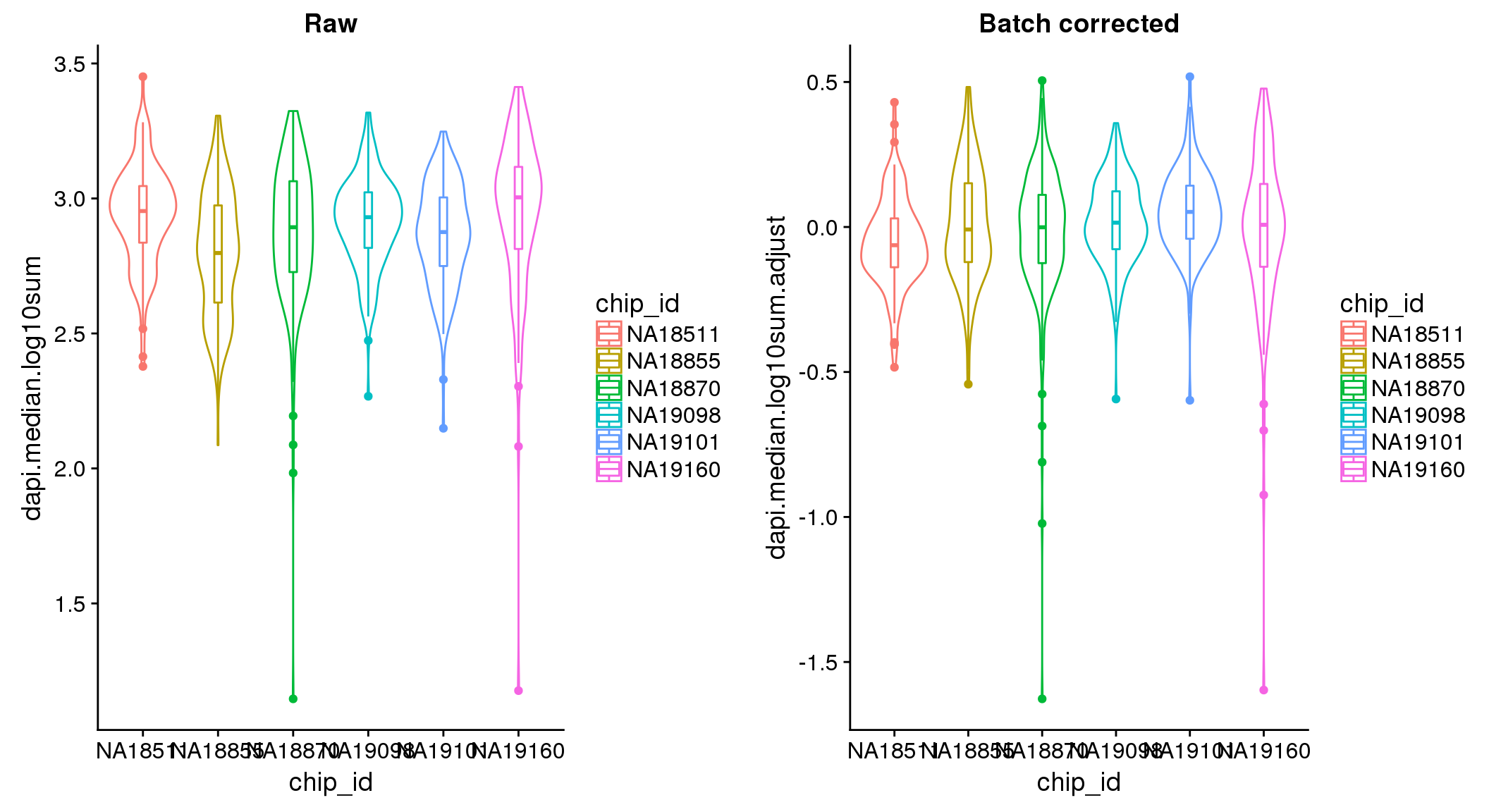
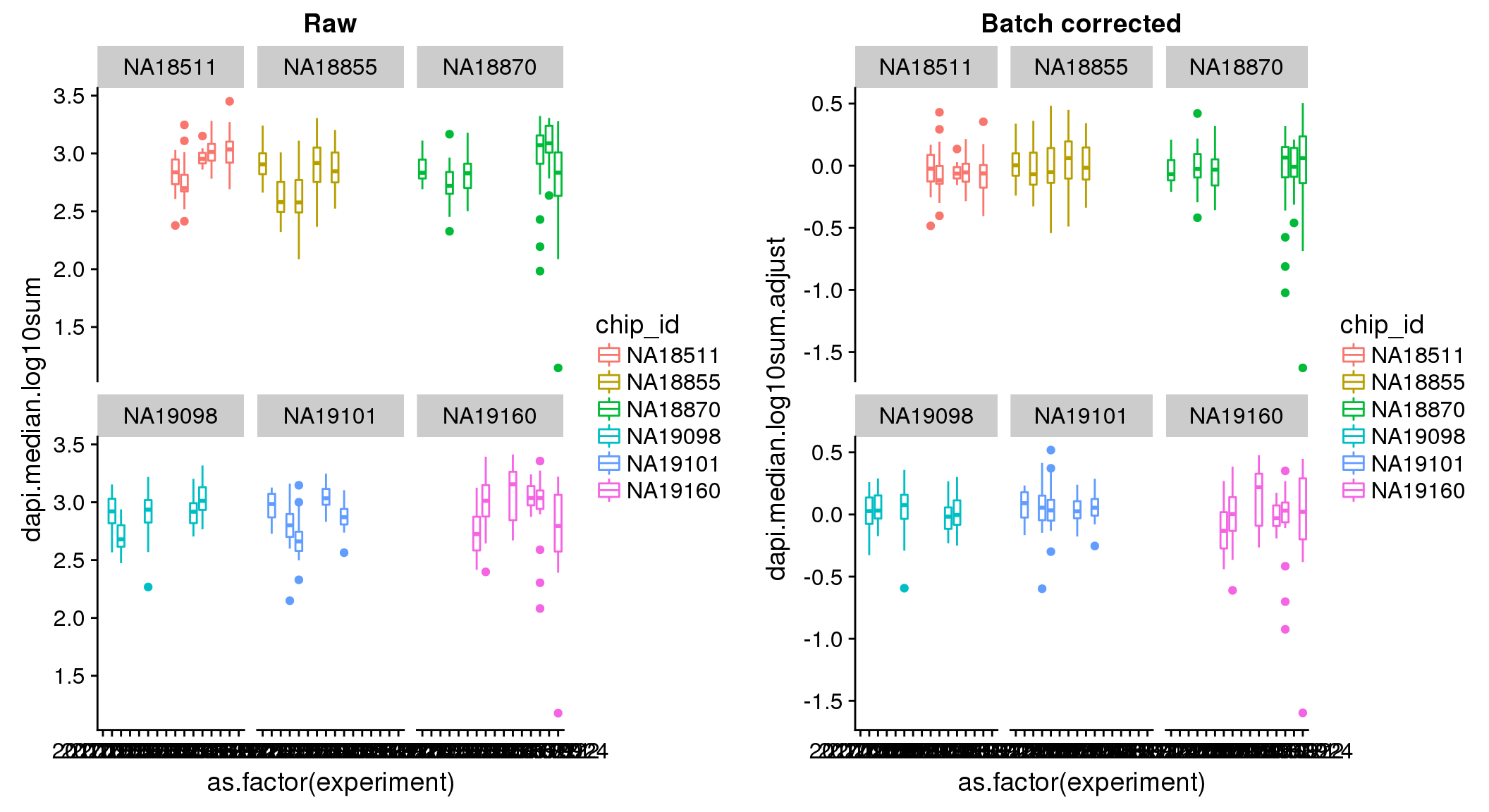
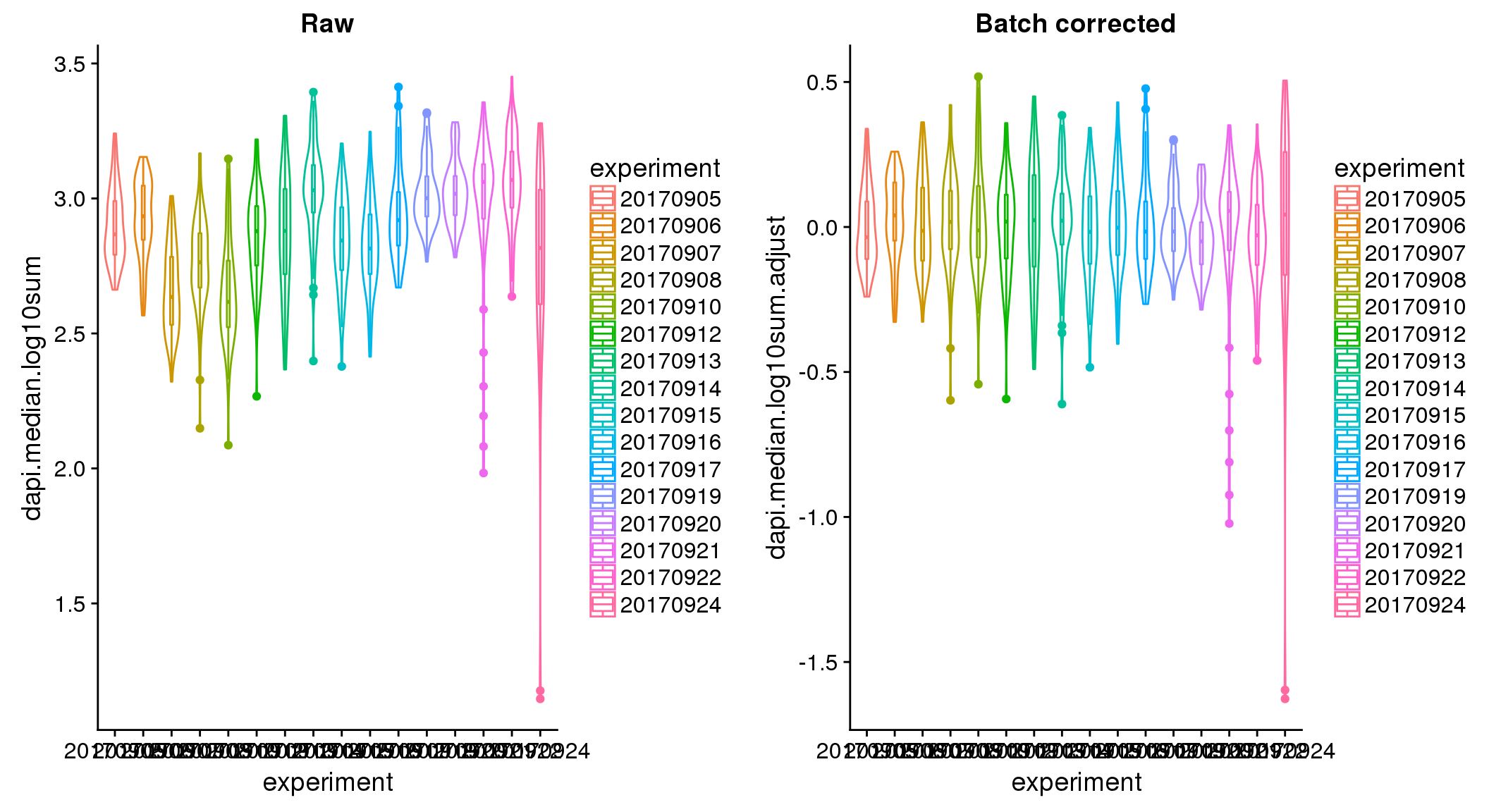
ANOVA on the batch-corrected DAPI shows no significant plate effect.
aov.ibd(dapi.median.log10sum.adjust~factor(chip_id)+factor(experiment),data=pdata)$ANOVA.table
Anova Table (Type III tests)
Response: dapi.median.log10sum.adjust
Sum Sq Df F value Pr(>F)
(Intercept) 0.087 1 2.2619 0.13292
factor(chip_id) 0.531 5 2.7583 0.01752 *
factor(experiment) 0.000 15 0.0000 1.00000
Residuals 37.275 969
---
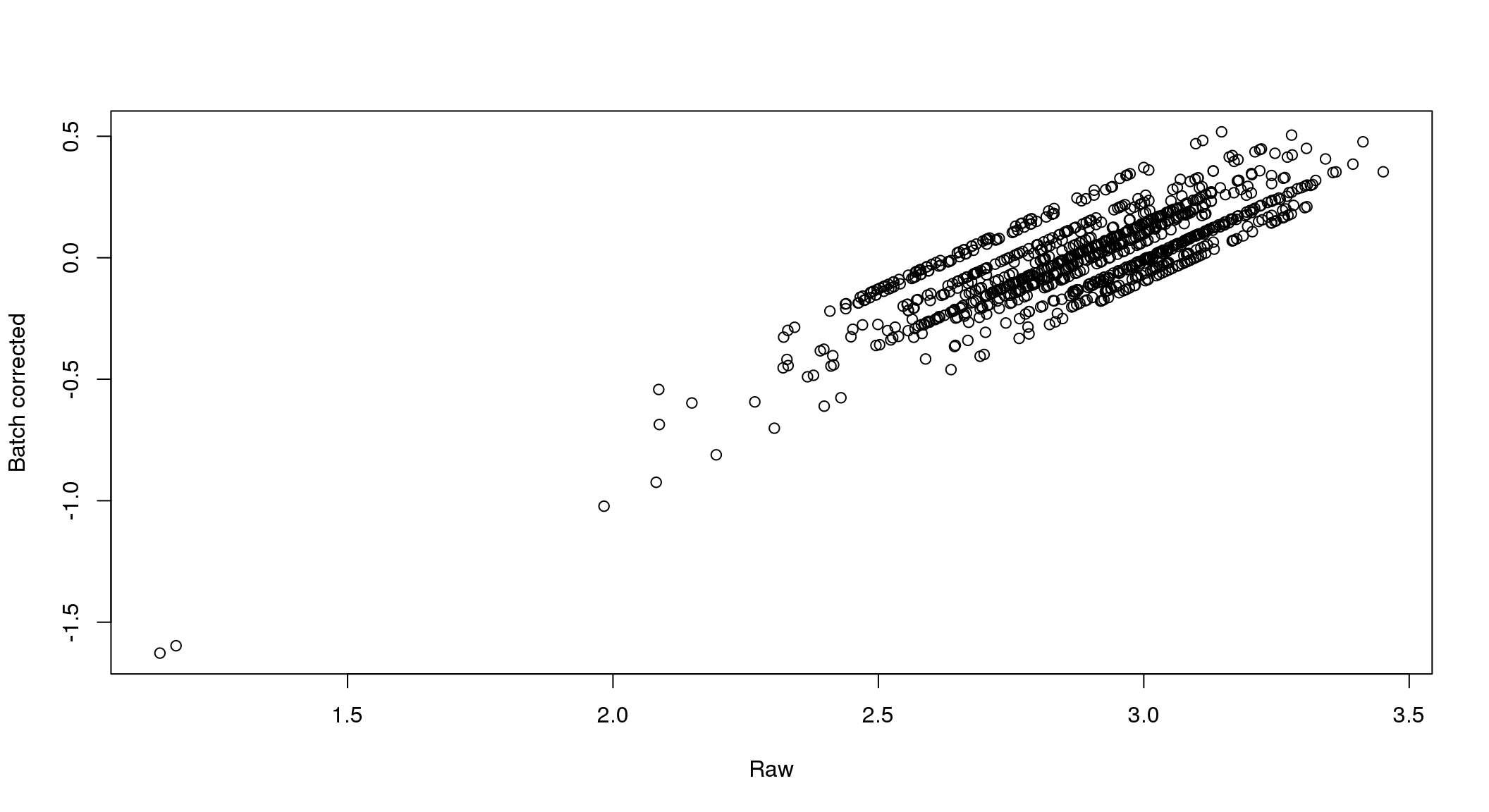
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1bi-axial distribution
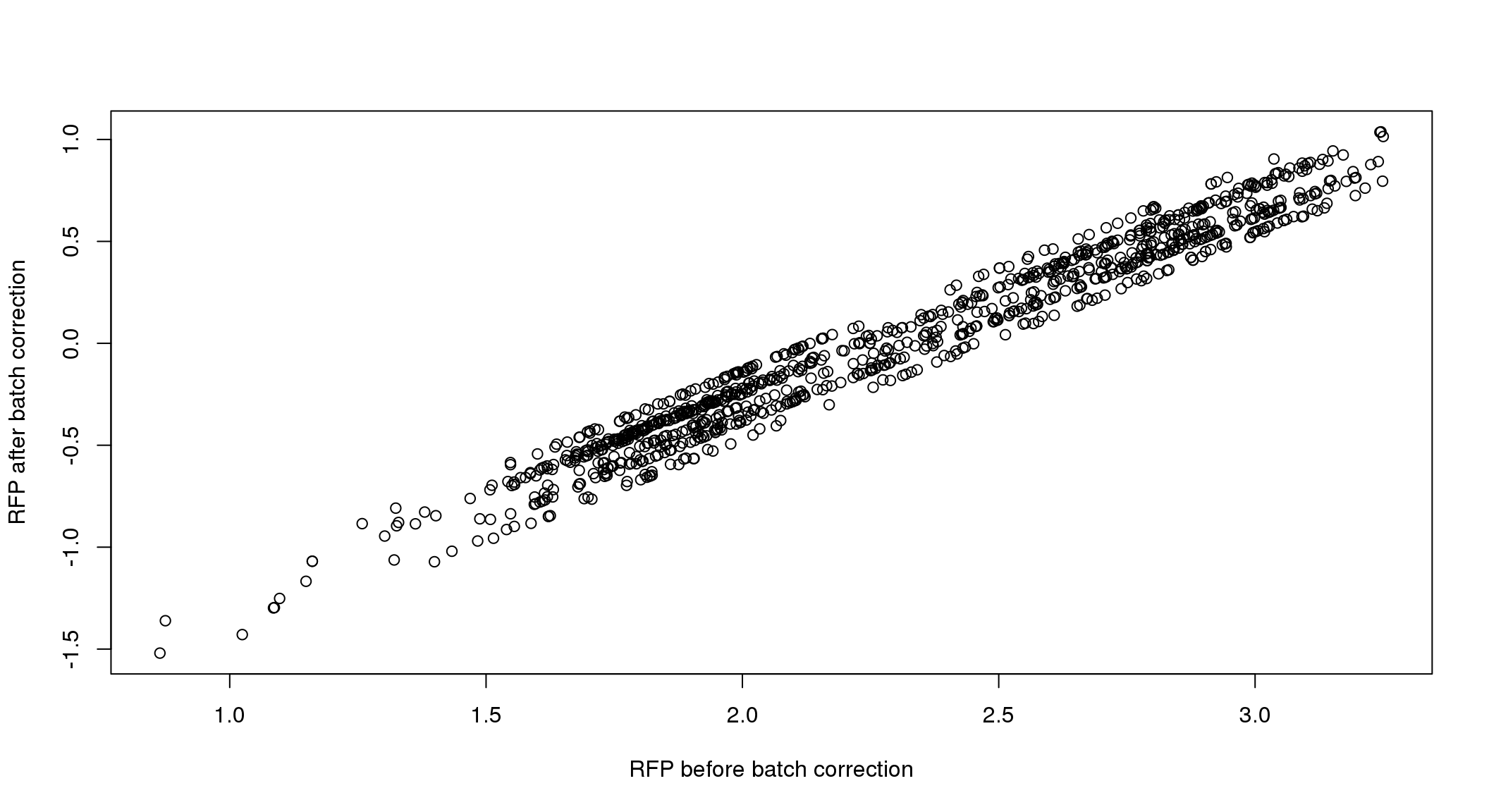
There seems to be a decrease in between-sample point distance in the data corrected for batch effect.
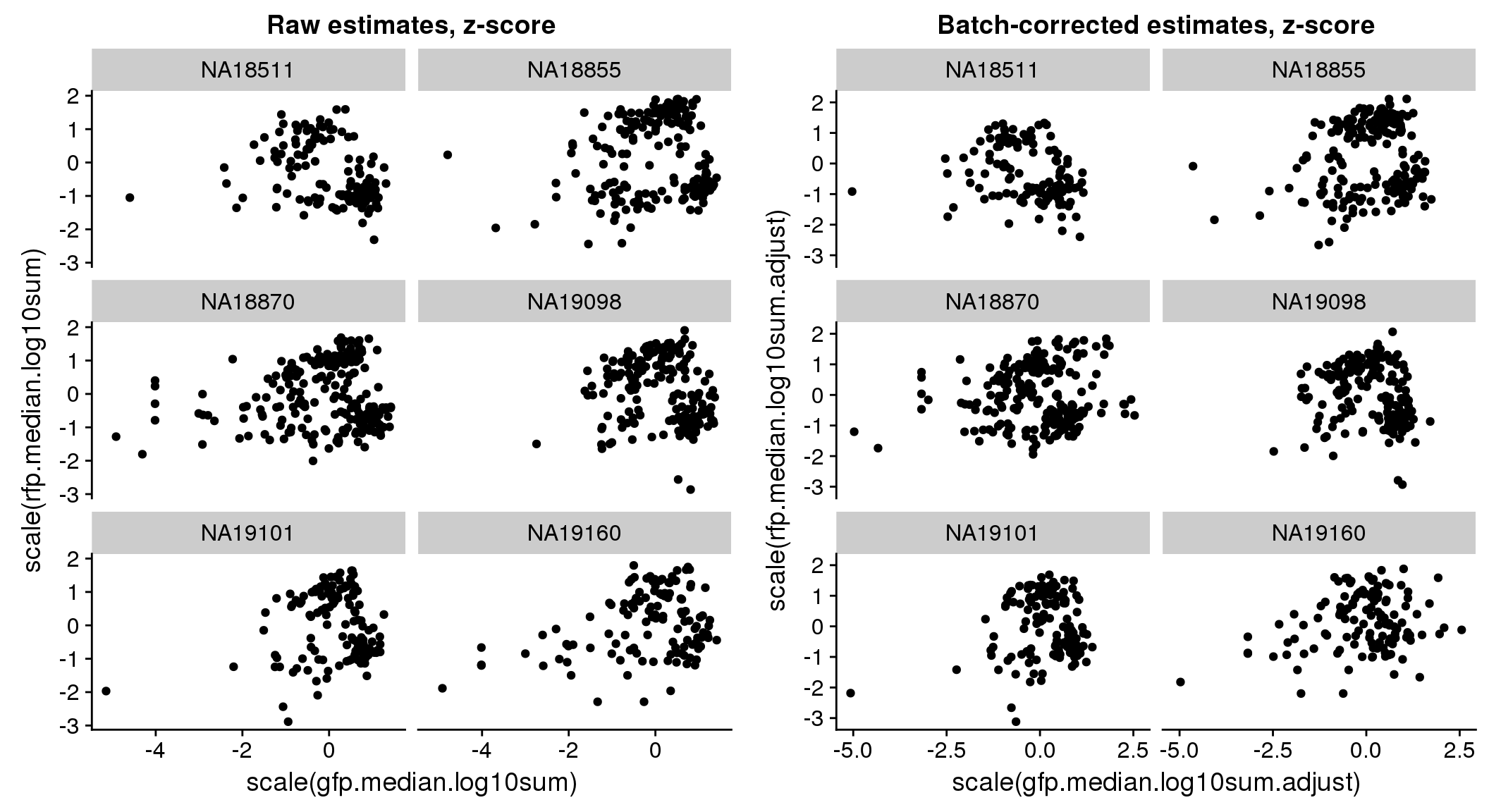
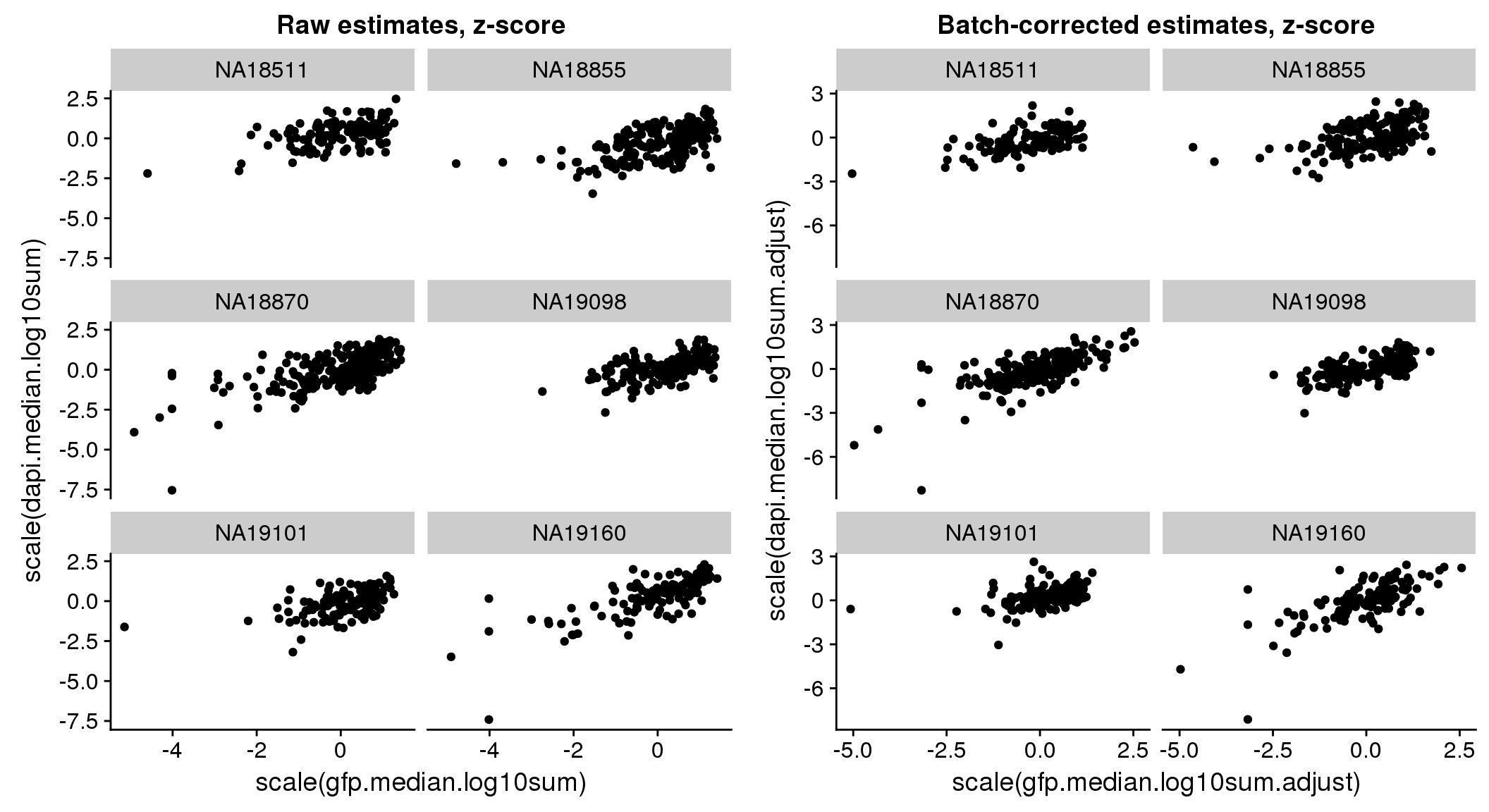
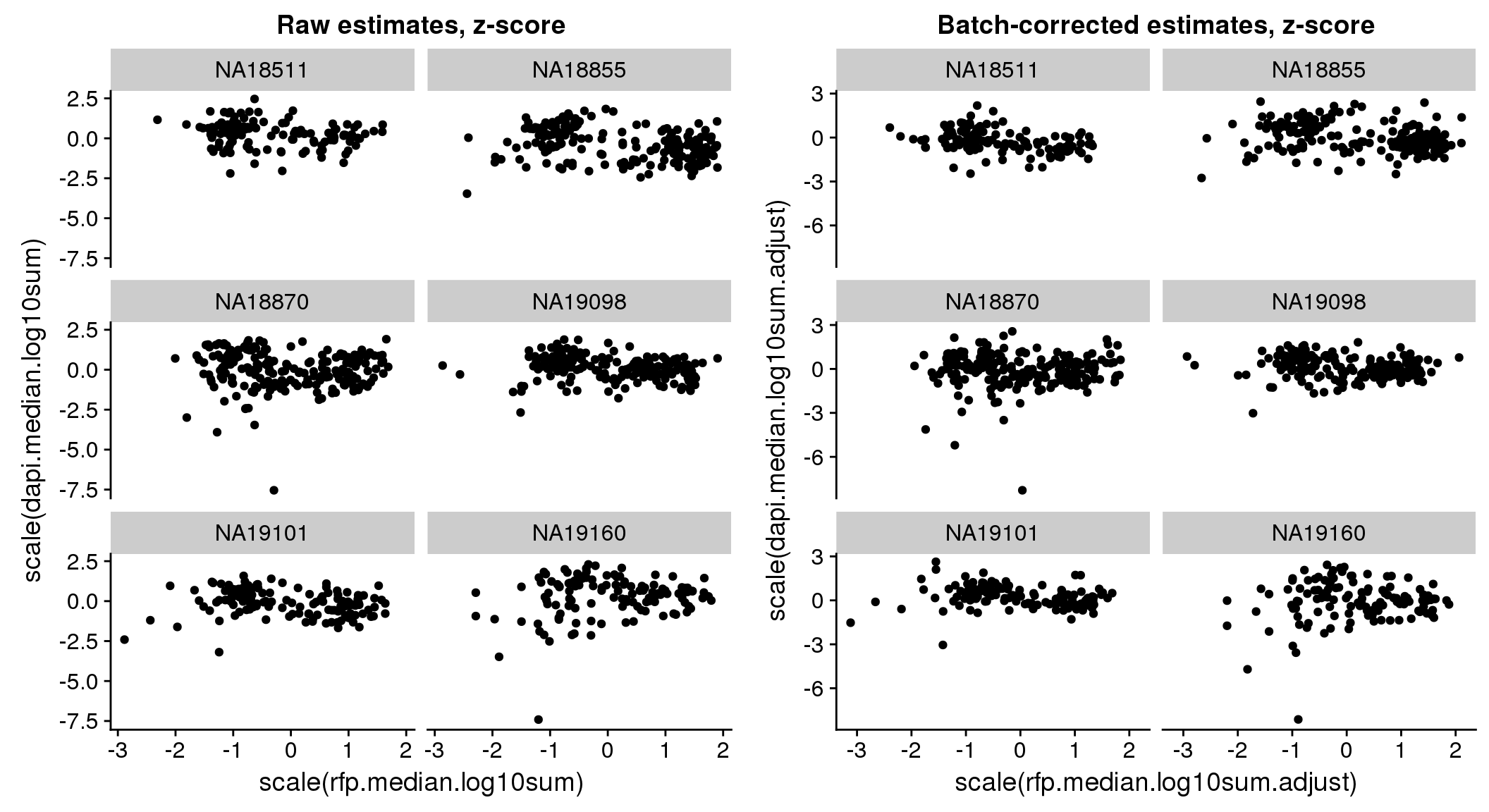
Output
Save corrected data to a temporary output folder.
saveRDS(pdata, file = "../output/images-normalize-anova.Rmd/pdata-adj.rds")Session information
R version 3.4.1 (2017-06-30)
Platform: x86_64-redhat-linux-gnu (64-bit)
Running under: Scientific Linux 7.2 (Nitrogen)
Matrix products: default
BLAS/LAPACK: /usr/lib64/R/lib/libRblas.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] parallel stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] ibd_1.2 multcompView_0.1-7 lsmeans_2.27-61
[4] car_2.1-6 MASS_7.3-47 lpSolve_5.6.13
[7] scales_0.5.0 Biobase_2.38.0 BiocGenerics_0.24.0
[10] RColorBrewer_1.1-2 wesanderson_0.3.4 cowplot_0.9.2
[13] ggplot2_2.2.1 dplyr_0.7.4 data.table_1.10.4-3
loaded via a namespace (and not attached):
[1] zoo_1.8-1 splines_3.4.1 lattice_0.20-35
[4] colorspace_1.3-2 htmltools_0.3.6 yaml_2.1.16
[7] mgcv_1.8-17 survival_2.41-3 rlang_0.1.6
[10] pillar_1.1.0 nloptr_1.0.4 glue_1.2.0
[13] bindrcpp_0.2 multcomp_1.4-8 bindr_0.1
[16] plyr_1.8.4 stringr_1.2.0 MatrixModels_0.4-1
[19] munsell_0.4.3 gtable_0.2.0 mvtnorm_1.0-7
[22] coda_0.19-1 codetools_0.2-15 evaluate_0.10.1
[25] labeling_0.3 knitr_1.19 SparseM_1.77
[28] quantreg_5.35 pbkrtest_0.4-7 TH.data_1.0-8
[31] Rcpp_0.12.15 xtable_1.8-2 backports_1.1.2
[34] lme4_1.1-15 digest_0.6.15 stringi_1.1.6
[37] grid_3.4.1 rprojroot_1.3-2 tools_3.4.1
[40] sandwich_2.4-0 magrittr_1.5 lazyeval_0.2.1
[43] tibble_1.4.2 pkgconfig_2.0.1 Matrix_1.2-10
[46] estimability_1.2 assertthat_0.2.0 minqa_1.2.4
[49] rmarkdown_1.8 R6_2.2.2 nnet_7.3-12
[52] nlme_3.1-131 git2r_0.21.0 compiler_3.4.1 This R Markdown site was created with workflowr