Yahoo! benchmark
For successful launch of fast, big data projects, try DataTorrent’s AppFactory.
Over the last year, Big Data Streaming computation engines such as Apache Apex, Apache Flink, Apache Spark (Spark Streaming), Google Dataflow and many others gained significant popularity among software development community and business users as such platforms provide additional capabilities that batch processing engines cannot deliver. There is a large number of use cases across various vertical markets (advertisement, industrial IoT, financial services and telecom) where events must be processed and acted upon as soon as they occur. Latency has become an important part of the service level agreement (SLA) as even a small delay in the data analysis may lead to a significant business loss. Another important term of SLA is throughput. Streaming platforms should be able to not only process a huge number of records but should be capable of handling a large and non-uniform workload without significantly impacting latency.
A standard benchmark that can be used to compare throughput and latency of streaming computation engines is necessary as more and more organizations are interested in Big Data Streaming engines and need to make a decision on which platform to choose. In the absence of a standard benchmark, Yahoo! used simple advertisement use case to compare throughput and latency for Apache Storm, Flink, and Spark Streaming. For background, the simplified use case is to consume advertisement impressions in a form of JSON objects from Apache Kafka, parse/deserialize JSON to POJO, filter approximately one-third of impressions based on the impression type, lookup advertisement campaign, aggregate them into 10-seconds window buckets for every distinct campaign and write aggregated results to a NoSQL database for subsequent analysis (for more details please see Benchmarking Streaming Computation Engines at Yahoo! and Performance Comparison of Streaming Big Data Platforms).
The result of the Yahoo! benchmark suggests that Spark Streaming, while capable of handling similar throughput as two other platforms, is not able to meet the required one second latency SLA. The two other engines delivered comparable latency SLAs for the workloads used in that benchmark.
After Jamie Grier from the data Artisans team extended the Yahoo! streaming benchmark to much higher than the original throughput of 50K-170K events/second Flink significantly outperformed Storm. Presumably due to faster CPUs and network connections between compute nodes than in the Yahoo! setup, Storm was able to process 400K events/second with the computed latency between 0.3 and 1.1 seconds, while Flink saturated the 1Gb network connection to Kafka at 3 million events/second with the computed latency between 0.3 and 0.8 seconds (for more details please see Jamie Grier’s blog post Extending the Yahoo! Streaming Benchmark).
Benchmarking: Comparing Apache Apex and Apache Flink
The decision to add Apex to the test matrix was a no-brainer. To run benchmarks we (few engineers from DataTorrent) used the company development cluster. Below is the detailed specification:
- 13 nodes cluster running Hadoop 2.6.0/CDH 5.4.9.
- Each node has 2 Intel(R) Xeon(R) E5-2630@2.30GHz CPUs (total 24 cores w/ hyperthreading) and 252 GB RAM.
- All nodes have 6 Hitachi HUA72303 3TB hard drives connected to a single I/O controller.
- 10 Gb Ethernet connection between nodes.
- 4 additional nodes (w/ the same hardware spec as above) running Kafka 0.8.2 brokers each serving 5 Kafka partitions. Kafka nodes are connected to the same switch as Hadoop cluster nodes.
Due to the difference in the hardware specifications, we can not directly compare Apex runs against Yahoo! or data Artisans results. Instead, we ran both Apex and Flink, which outperformed both Spark Streaming (in the original Yahoo! benchmark) and Storm (in the data Artisans runs), in our environment and compared results. For Flink, we used extended benchmark source code available on GitHub and 1.0.2 Flink binary distribution. The source code for the Apex benchmark application is available on GitHub as well. The benchmark was executed against Apex 3.4.0 release.
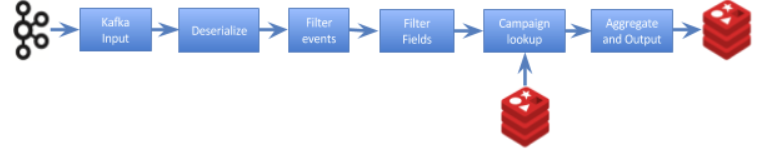
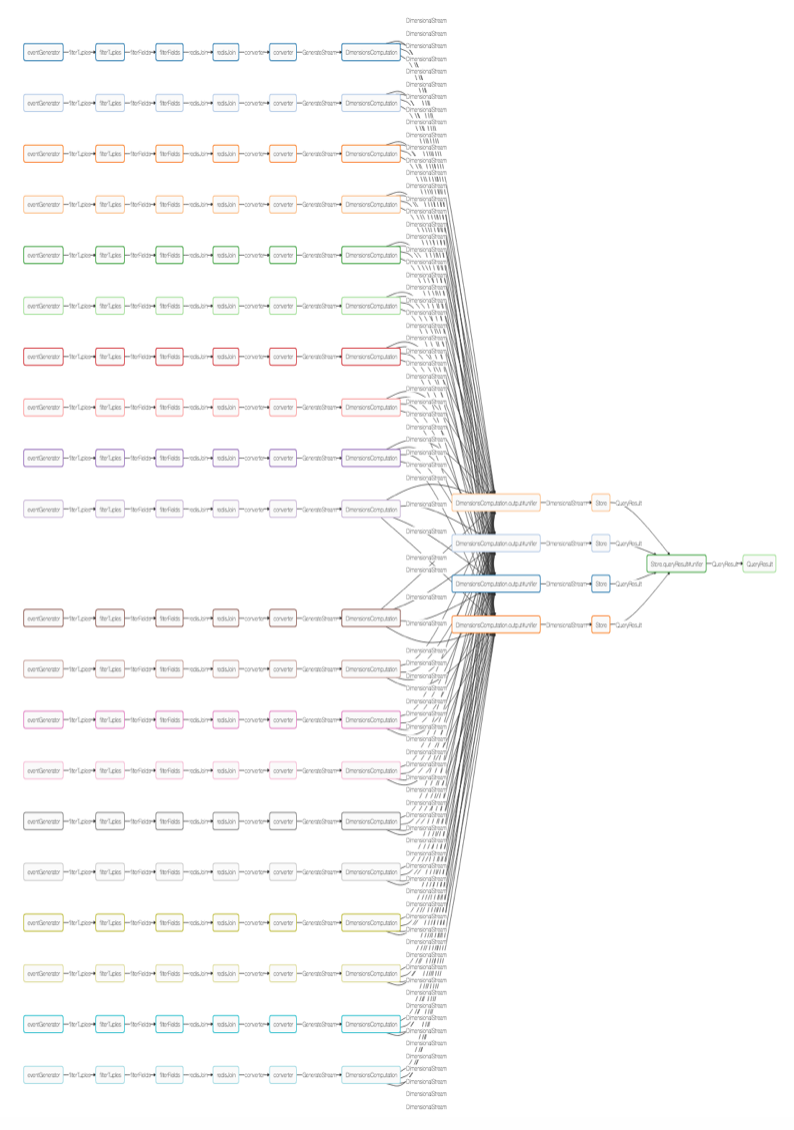
Apex benchmark application. Logical and Physical DAG.
Apex engine translates the logical DAG into the physical execution plan using streams locality and operators partitioning scheme.

In the case of Yahoo! benchmark Kafka partitioning provides an obvious scheme to parallelize events/tuples processing all the way up to the campaignProcessor operator that is responsible for aggregating distinct campaigns into 10-seconds buckets and writing them to Redis. This translates to 20 independent parallel pipelines that read messages from the corresponding Kafka partition, deserialize them into POJO and process individual POJOs.
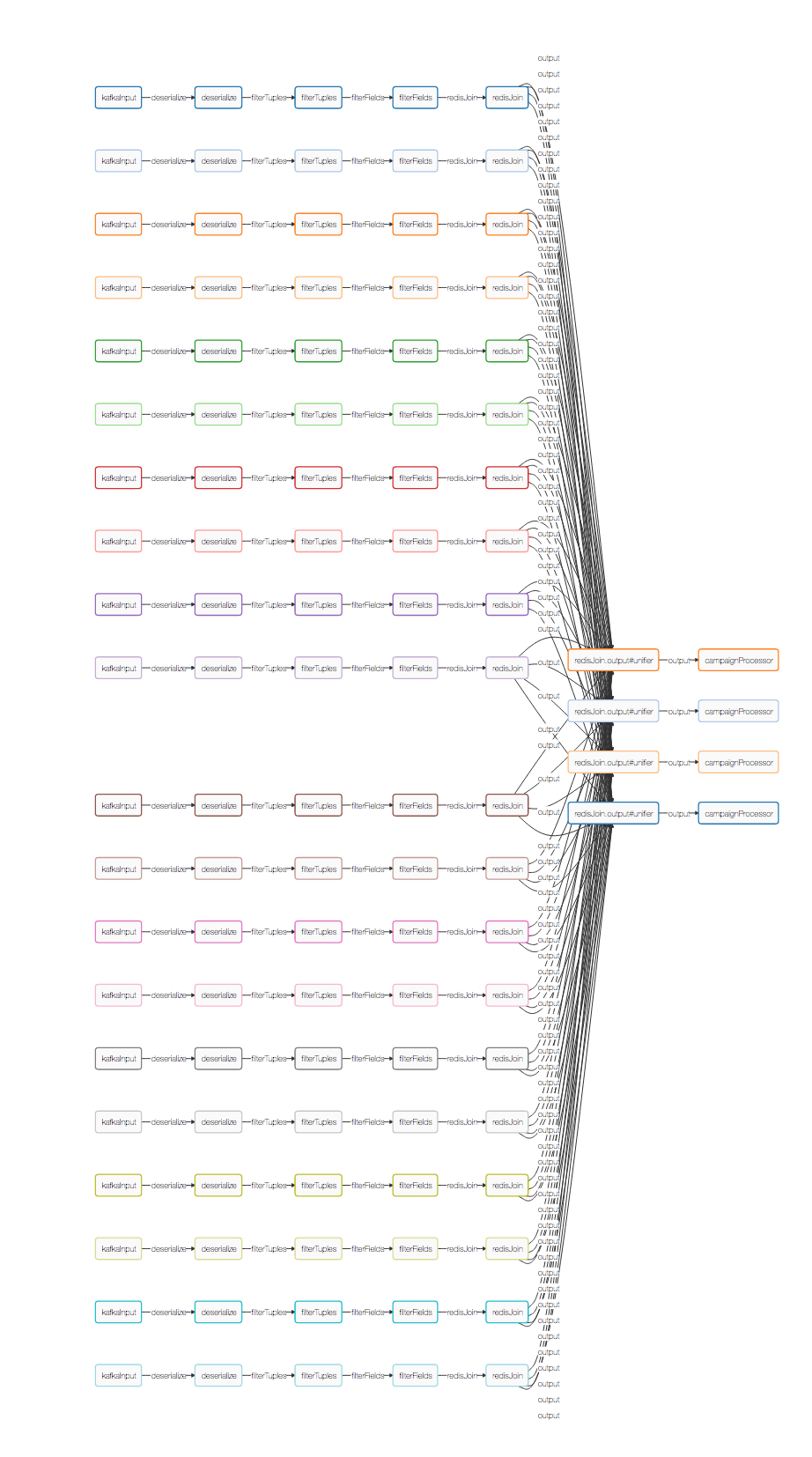
Prior to aggregation, tuples are shuffled using campaign id and MxN partitioning scheme is applied. Due to a small number of unique campaigns used in the Yahoo! benchmark it was sufficient to allocate 4 partitions to handle 10 seconds window aggregation and write to Redis.
The color of an operator in the Physical DAG indicates co-located operators. Operators with the same color are deployed into the same YARN container.
Apex vs Flink. Benchmark results.
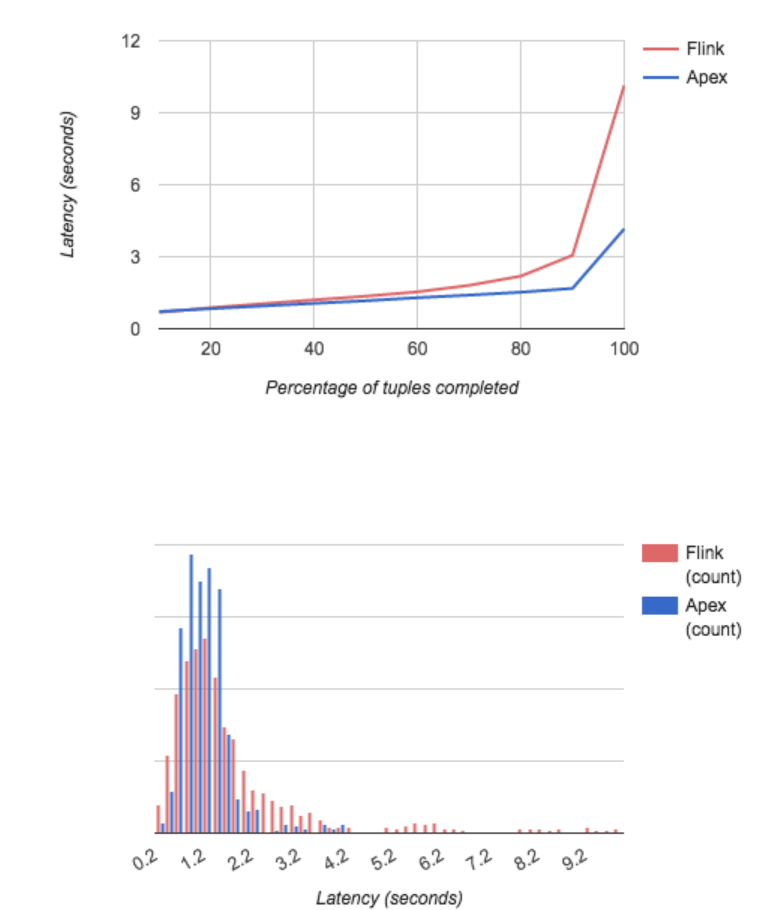
In the DataTorrent setup, each Kafka broker was able to handle approximately 675K 288 bytes long messages/second or 135K messages/second for each partition. With 4 brokers that allowed us to publish approximately 2.7 million events/second similar to the throughput achieved by Jamie Grier for Flink. Both Apex and Flink exposed similar latency distribution. The majority of events processing were completed within 2 seconds, but small amounts of events were delayed by up to 10 seconds. Further analysis of the spikes in the events processing time pointed to Kafka as the main contributor to the latency. Each time the latency exceeded 4 seconds we saw an error (kafka.common.UnknownException) in the Kafka consumer API and a corresponding error on the Kafka broker side:
ERROR [Replica Manager on Broker XXX]: Error when processing fetch request for partition [XXX,5] offset 150998650 from consumer with correlation id 0. Possible cause: Attempt to read with a maximum offset (150998624) less than the start offset (150998650). (kafka.server.ReplicaManager)
that may be related to a known KAFKA-725 JIRA. With 2.7 million events/seconds throughput the error always occurs at least once during 20 minutes period that we used to run both Apex and Flink benchmarks.
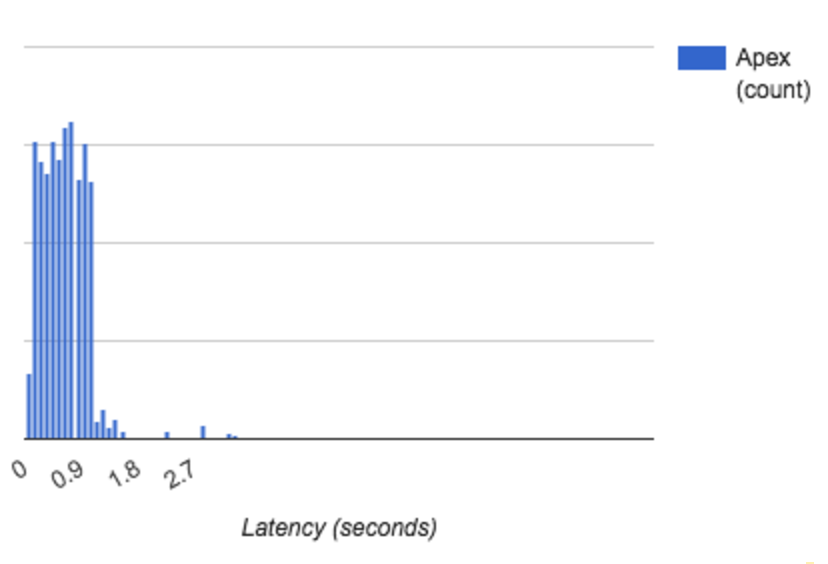
Even without the error, when we lowered throughput to 150K events/second or executed the benchmark for a shorter period of time, it sometimes took up to 3 seconds for events to be delivered to Kafka, be processed by the Kafka broker and become available for further processing.
It is also necessary to note that the actual accuracy of the latency computation in the Yahoo!benchmark is 10 seconds instead of the declared goal of 1 second as the latency is computed as a difference between processing time and the corresponding 10 second end window generation time (blue arrow).
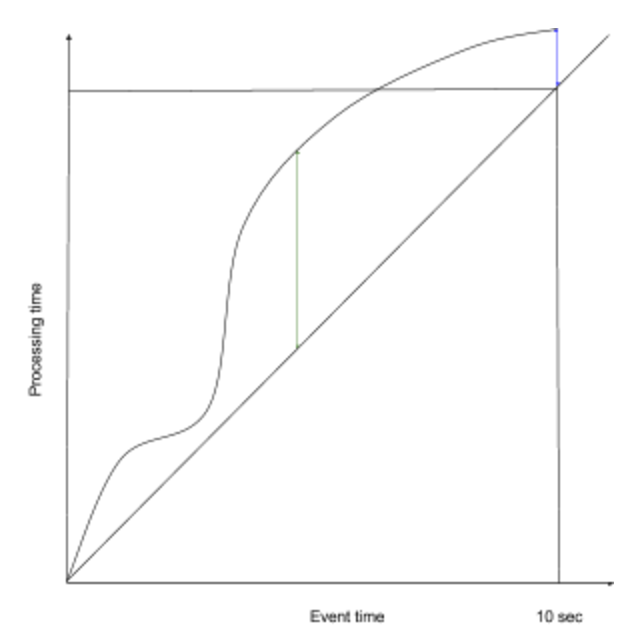
The proper latency calculation should use the maximum difference between event processing time and event generation time (green arrow). In a case where 10 seconds delay is introduced at the beginning of a 10 seconds window, but a platform is able to catch up at the end of the aggregation window, the latency computation would be wrong by almost 10 seconds. As a result, a delay in the event processing caused by JVM garbage collection, connectivity issues or an error on the Kafka side may not be reported properly.
DataTorrent Dimensional compute
To further evaluate Apex platform ability to handle high throughputs with low events processing time latency it was necessary to remove Kafka and to integrate event generation directly into the Apex DAG. To scale on the number of campaign advertisements we introduced DataTorrent dimensional compute operator in place of the campaignProcessor and dropped dependency on Redis for storing events latencies and campaign aggregation counts as DataTorrent dimensional computation operator and HDHT store provide required capability and are optimized to work together in Apex.

The constructed dimensional compute physical DAG is similar to the Apex physical DAG in Yahoo! benchmark except for the last part of the DAG. It is worth mentioning that the campaign aggregations are done in three stages. First, partial aggregation is done in the DimensionsComputation, second, after events are shuffled by campaign id, they are further aggregated in the DimensionsComputation unifiers and the final results are computed in the Store that handles late event arrivals.
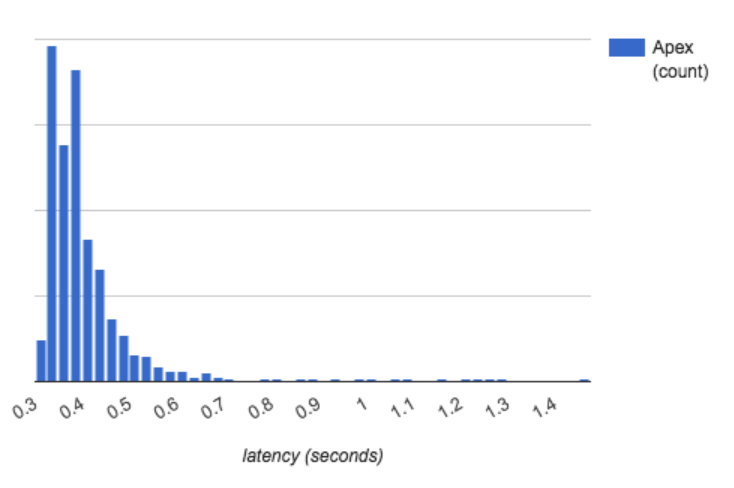
With the above modifications, Apex throughput reached 43 million events per second with more than 90 percent of events processed with the latency less than 0.5 seconds running on the same development Hadoop cluster as the Yahoo! benchmark.
Conclusions and further work
The results of the modified benchmark prove that Streaming computation engines are capable of handling millions events per second with extremely low events processing latency of a few hundreds milliseconds. For a benchmark to properly measure Big Data Streaming platform performance, it should be able to ingest millions events per second without introducing latency. The benchmark designed by Yahoo! to mimic the advertisement use case helps to isolate high latency or lower throughput platforms, but has limited ability to benchmark several Streaming platforms such as Apex or Flink that offer both high throughput and low latency. Additionally, this benchmark does not cover financial services, industrial IoT, telecom and other verticals workloads and it is unlikely that it will be adopted by the community as a standard Big Data Streaming benchmark.
I guess, that over the next few years, there will be several attempts to define a suite of benchmark tests for Big Data Streaming engines before a standard benchmark will be designed and implemented.
DataTorrent helps our customers get into production quickly using open source technologies to handle real-time, data-in-motion, fast, big data for critical business outcomes. Using the best-of-breed solutions in open source, we harden the open source applications to make them act and look as one through our unique IP that we call Apoxi™. Apoxi is a framework that gives you the power to manage those open source applications reliably just like you do with your proprietary enterprise software applications, lowering the time to value (TTV) with total lower cost of ownership (TCO). To get started, you can download DataTorrent RTS or micro data services from the DataTorrent AppFactory.
Leave A Comment