History
Big Data has an interesting history. In the past few years, massive amounts of data have been generated for processing and analytics, and enterprises have been facing problems processing ever increasing data size. In order to process this increasing data size, the way was to scale up but scaling up was costly and resulted in vendor lock-in. So they started to look at scaling out. Enter the Big Data ecosystem with projects like Hadoop, YARN, Spark which fairly satisfied Big Data processing needs. At the same time, the traditional SQL based database processing paradigm was and is still being widely used for various data processing, aggregation and analytics needs; so SQL is a very popular skill-set. And that is the genesis of notions such as SQL-on-Hadoop and related projects such as Apache Hive, Apache Drill and Apache Ignite.
Apache Apex is an enterprise-grade streaming technology which processes data at a very high rate with low latency in a fault tolerant way while providing processing guarantees like exactly-once
Why we did what we did?
It has become apparent that the Big Data processing engines still work in batch mode and although they are able to process large amounts of data, the time required to perform analytics and generate results has become critical. In spite of ever increasing data, users are expecting to see quick results to help them make quick and accurate decisions. Usefulness of results starts to decrease as processing takes longer and longer, which is where one begins to see the value of real-time processing and analytics. Enter streaming technologies such as Apache Apex which is an enterprise-grade streaming technology which processes data at a very high throughput with low latency in a fault tolerant way while providing processing guarantees like exactly-once. In all this change in processing requirement, the requirement related to SQL still remained constant. Apache Calcite, another very popular and widely used project in Apache, realized the need for a framework which can provide an efficient way of translating streaming paradigms on SQL.
We took this as an opportunity and integrated Apache Apex with Apache Calcite to allow SQL-lovers and experts to work with SQL for their data analytics but now on data-in-motion.
Apache Apex-Calcite integration allows SQL-lovers and experts to work with SQL for their data analytics but now on data-in-motion
What is Apex-Calcite Integration?
First, we would like to give a brief about Apache Calcite. Apache Calcite is a highly customizable engine for parsing and planning queries on data in a wide variety of formats. It allows database-like access and in particular a SQL interface and advanced query optimization for data not residing in traditional databases.
Apache Calcite parses SQL and converts SQL Node Tree to Relational Algebra which is optimized further using VolcanoPlanner or HepPlanner to create a processing pipeline. This pipeline of relational algebra is converted by Apache Apex engine to its set of operators to perform business logic on data-in-motion. This is nothing but a DAG in Apex terminology.
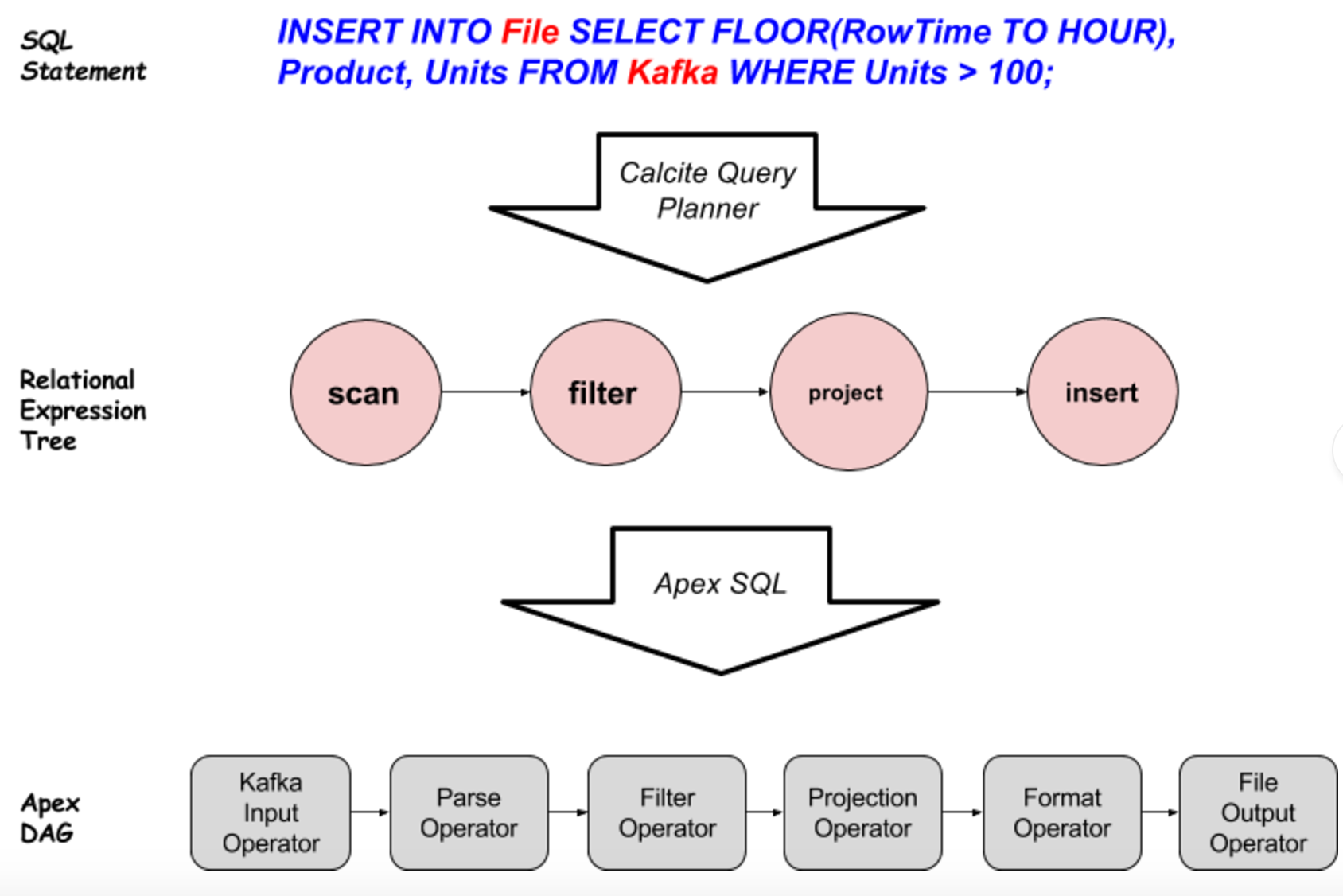
Above figure explains how SQL query gets converted to Apex DAG.
- The received query from a user is parsed by Calcite’s query parser.
- The query parser returns the SQL Node Tree to Query Planner and optimizer which converts the SQL Node Tree to Relation Expression Tree.
- This Relation Expression Tree is received by Apache Apex’s SQL module to finally convert to an Apex DAG having series of operators.
One peculiarity that can be seen in above example is the data source, and data destination are not RDBMS systems. This is because Calcite allows Apex to register table sources and destinations as anything which can return a row type results. So a “scan” relational expression gets converted to “KafkaInputOperator + ParseOperator”, a result of which is series of POJO reflecting a Row Type. Similarly, the “insert” Relational Expression translated to “FormatOperator + FileOutputOperator”.
How to use SQL with Apache Apex?
SQL support of Apache Apex (malhar-sql) resides in the open source library of operators named Malhar which is a part of the Apex ecosystem.
Apex Malhar contains a large set of operators which are directly used when SQL is translated to Apex DAG. These operators give you production level stability and scalability.
Let’s take an example to explain in depth.
To use SQL support in Apex, you’ll have to create an Apex application using maven archetype as mentioned here.
Once the project is generated, the boilerplate in populate DAG looks like following:
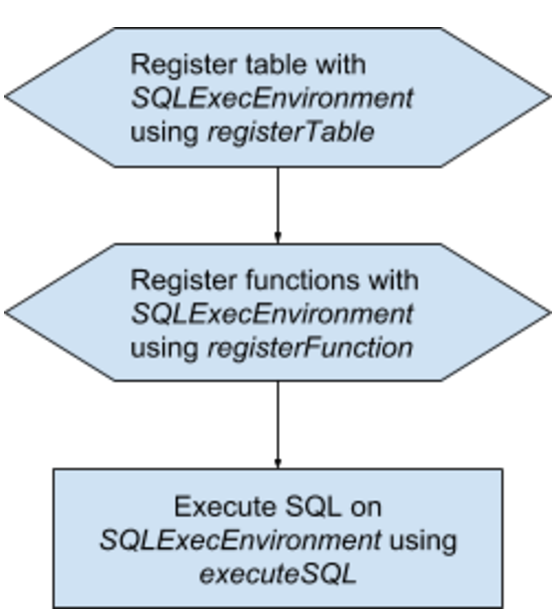
SQLExecEnvironment.getEnvironment()
.registerTable(“ORDERS”, new KafkaEndpoint(brokerList, topicList, new CSVMessageFormat(schemaDef)))
.registerTable(“SALES”, new FileEndpoint(destFolder, destFileName, new CSVMessageFormat(schemaOut)))
.registerFunction(“APEXCONCAT”, Application.class, “apex_concat_str”)
.executeSQL(dag,
“INSERT INTO SALES “ +
“SELECT STREAM ROWTIME, FLOOR(ROWTIME TO DAY), APEXCONCAT(‘OILPAINT’,SUBSTRING(PRODUCT, 6, 7) “ +
“FROM ORDERS WHERE ID > 3 AND PRODUCT LIKE ‘paint%'”);
In above code snippet, SQLEecEnvironment.getEnvironment gives you access to a global SQL Execution Environment. All the operations happen in this environment.
The registerTable APIs lets you register a custom (can be non-RBDMS) table with the execution environment. For e.g., in the above case the user has registered a table called as ORDER. This API has two components, first is KafkaEndpoint which indicates that table is from Kafka and a CSVMessageFormat which says what is the format of record received from Kafka.
A similar table called SALES is registered but this time with FileEndpoint i.e. operations are file related.
A string concatenation function is registered using registerFunction API which makes sure that a scalar method called APEXCONCAT is available to SQL statement writer.
And finally, a SQL statement is executed containing a SELECT clause indicating a source of stream and INSERT clause indicating destination. Here the data is processed from ORDERS table i.e. Kafka source and inserted into SALES table i.e. File destination with CSV formatting.
executeSQL method internally converts the relational algebraic expression to an Apex specific DAG and operators and launch it on Apex.
With this small code, following resultant DAG gets generated and executed.

What are next steps?
Apache Calcite has a bunch of other interesting features that we would like to incorporate along with Apache Apex. One such feature being event time awareness. With the new windowing operators, operators being introduced in Apache Apex Malhar, a feature set related to Streaming Analytics opens up for integrations and that’s going to be our next work. This would include support for Tumbling Window, Hoping Window and Session Window based aggregations, sorting and much more. Watch out for an upcoming release on Apache Apex Malhar.
Other things in the roadmap include providing support for additional connectors and CLI like interface after which SQL developers practically won’t need to write any code i.e. just play with SQL and launch streaming application.
We encourage you to try out current SQL APIs and provide suggestions and feedback to improve on the work being done. The Apache Apex community is actively working on enhancing SQL support but at the same time, we would like to invite contributors who are willing to enhance this feature to make SQL users work with Apex without any restrictions.
Very nice work in integration of Calcite. Windowing is important in analytics and to do it over streaming big data will be excellent
Thanks Sidhartha.