Why another benchmark blog?
As engineers, we are skeptical of performance benchmarks developed and published by software vendors. Most of the time such benchmarks are biased towards the company’s own product in comparison to other vendors. Any reported advantage may be the result of selecting a specific use case better handled by the product or using optimized configuration for one’s own product compared to out of the box configuration for other vendors’ products.
So, why another blog on the topic? The reason I decided to write this blog is to explain the rationale behind DataTorrent’s effort to develop and maintain a benchmark performance suite, how the suite is used to certify various releases, and seek community opinion on how the performance benchmark may be improved.
Note: the performance numbers given here are only for reference and by no means a comprehensive performance evaluation of Apache APEX; performance numbers can vary depending on different configurations or different use cases.
Benchmark application.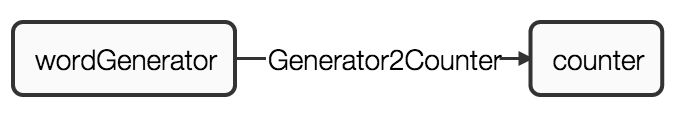
To evaluate the performance of the Apache APEX platform, we use Benchmark application that has a simple DAG with only two operators. The first operator (wordGenerator) emits tuples and the second operator (counter) counts tuples received. For such trivial operations, operators add minimum overhead to CPU and memory consumption allowing measurement of Apache APEX platform throughput. As operators don’t change from release to release, this application is suitable for comparing the platform performance across releases.
Tuples are byte arrays with configurable length, minimizing complexity of tuples serialization and at the same time allowing examination of performance of the platform against several different tuple sizes. The emitter (wordGenerator) operator may be configured to use the same byte array avoiding the operator induced garbage collection. Or it may be configured to allocate new byte array for every new tuple emitted, more closely simulating real application behavior.
The consumer (counter) operator collects the total number of tuples received and the wall-clock time in milliseconds passed between begin and end window. It writes the collected data to the log at the end of every 10th window.
The data stream (Generator2Counter) connects the first operator output port to the second operator input port. The benchmark suite exercises all possible configurations for the stream locality:
- thread local (THREAD_LOCAL) when both operators are deployed into the same thread within a container effectively serializing operators computation;
- container local (CONTAINER_LOCAL) when both operators are deployed into the same container and execute in two different threads;
- node local (NODE_LOCAL)[1] when operators are deployed into two different containers running on the same yarn node;
- rack local (RACK_LOCAL)[2] when operators are deployed into two different containers running on yarn nodes residing on the same rack
- no locality when operators are deployed into two different containers running on any hadoop cluster node.
Apache APEX release performance certification
The benchmark application is a part of Apache APEX release certification. It is executed on DataTorrent’s development Hadoop cluster by an automated script that launches the application with all supported Generator2Counter stream localities and 64, 128, 256, 512, 1024, 2048 and a tuple byte array length of 4096. The script collects the number of tuples emitted, the number of tuples processed and the counter operator latency for the running application and shuts down the application after it runs for 5 minutes, whereupon it moves on to the next configuration. For all configurations, the script runs between 6 and 8 hours depending on the development cluster load.
Benchmark results
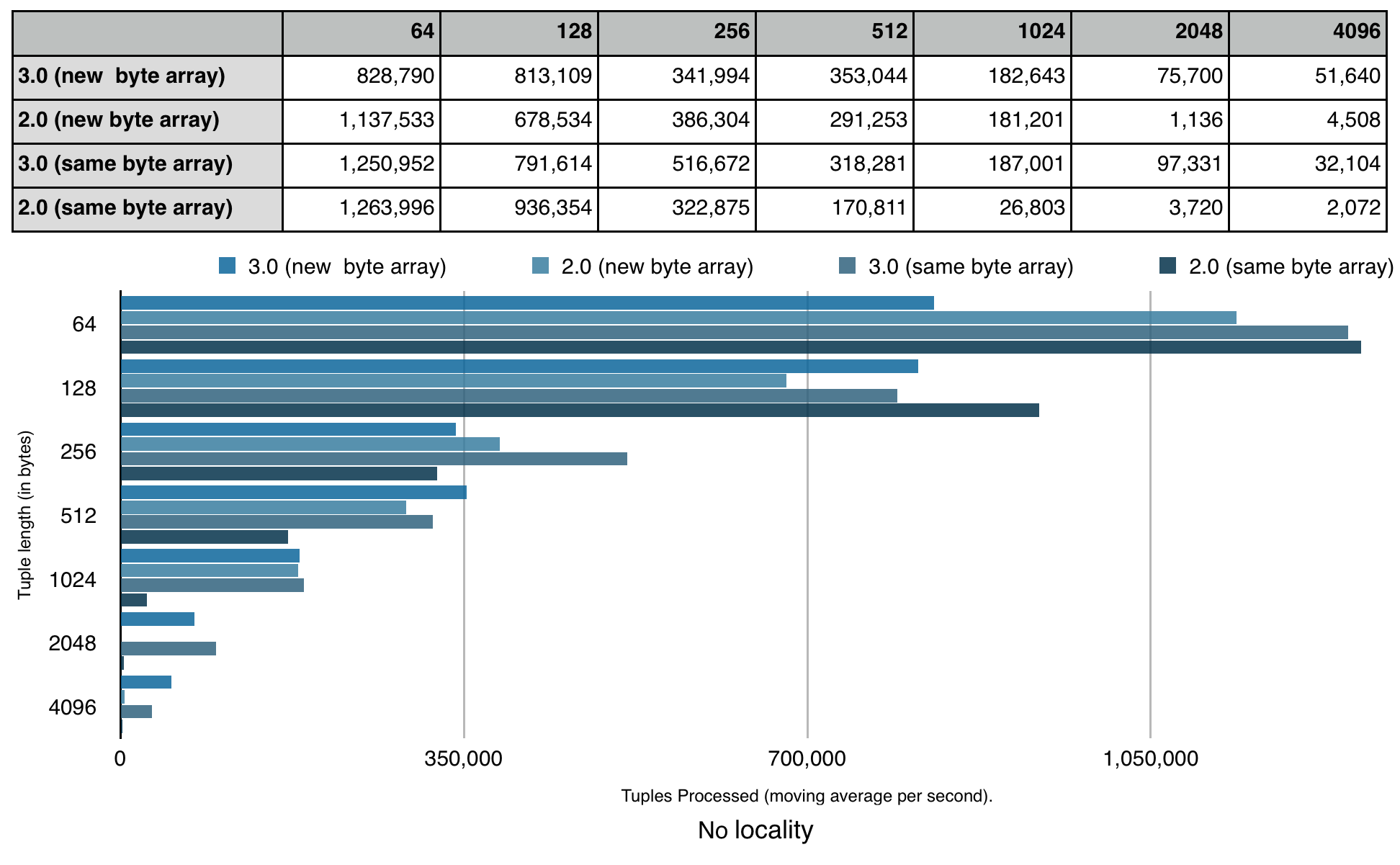
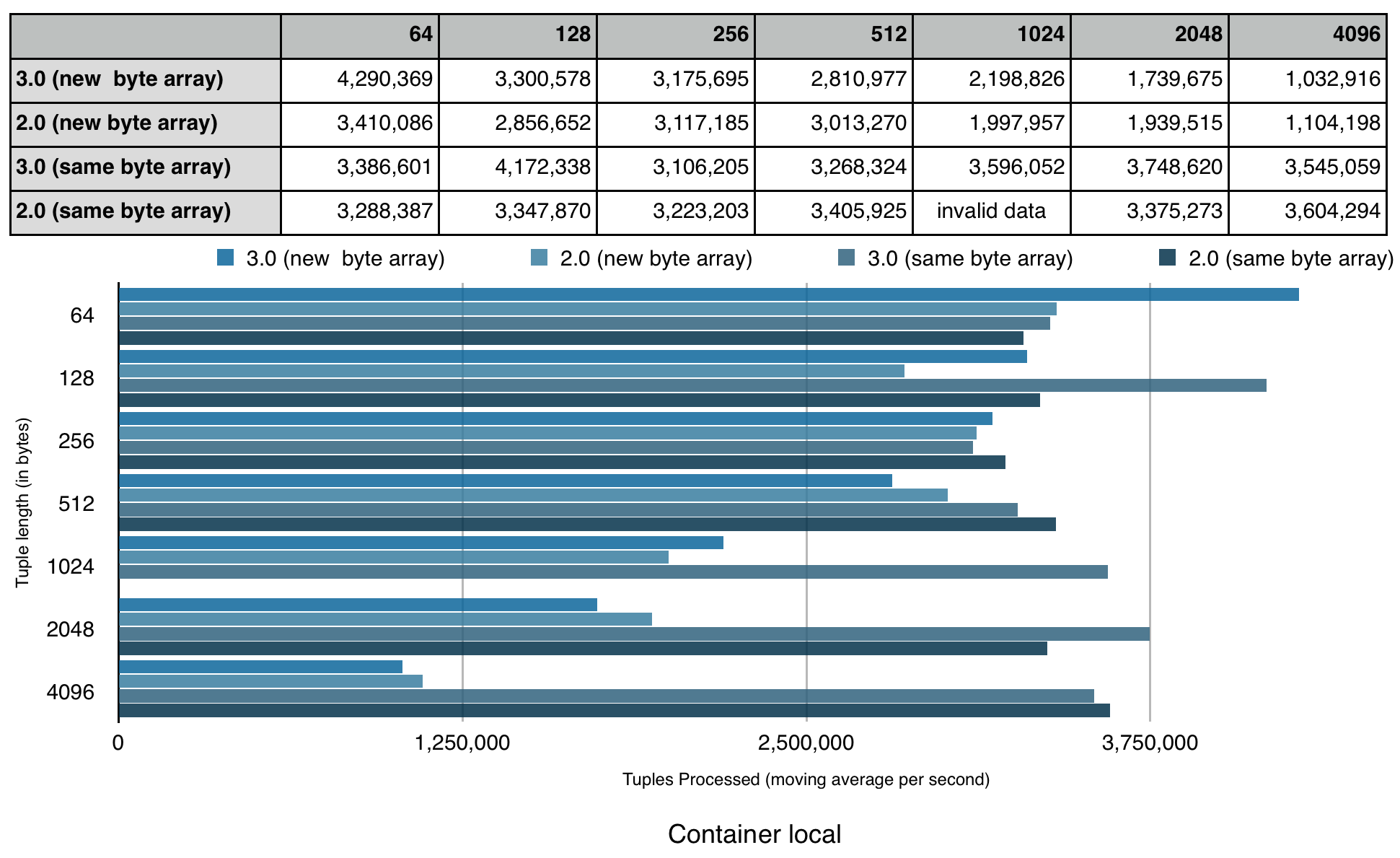
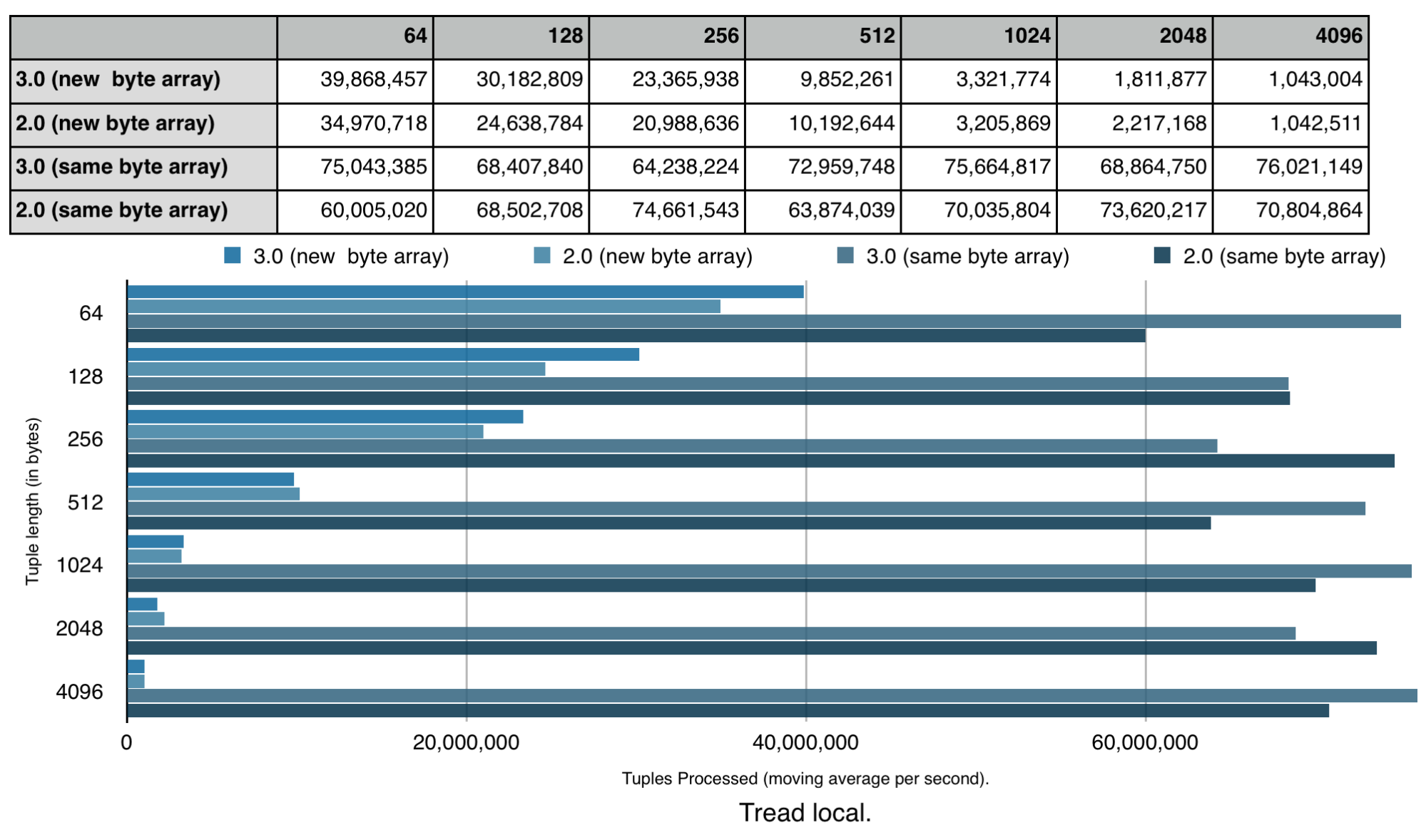
As each supported stream locality has distinct performance characteristics (with exception of rack local and no locality due to the development cluster being setup on a single rack), I use a separate chart for each stream locality.
Overall the results are self explanatory and I hope that anyone who uses, plans to use or plans to contribute to the Apache APEX project finds it useful. A few notes that seems to be worth mentioning:
- There is no performance regression in APEX release 3.0 compared to release 2.0
- Benchmark was executed with default settings for buffer server spooling (turned on by default in release 3.0 and off in release 2.0). As the result, the benchmark application required just 2 GB of memory for the wordGenerator operator container in release 3.0, while it was necessary to allocate 8 GB to the same in release 2.0
- When tuple size increases, JVM garbage collection starts to play a major role in performance benchmark compared to locality
- Thread local outperforms all other stream localities only for trivial operators that we specifically designed for the benchmark.
- The benchmark was performed on the development cluster while other developers were using it
[1] NODE_LOCAL is currently excluded from the benchmark test due to known limitation. Please see APEX-123
Leave A Comment