For successful launch of fast, big data projects, try DataTorrent’s AppFactory.
Big data is evolving in a big way. As it booms, the issue of fault tolerance becomes more and more exigent. What happens if a node fails? Will your application recover from the effects of data or process corruption?
In a conventional world, the simplest solution for such a problem would have been a restart of the offending processes from the beginning. However, that was the conventional world, with data sizes still within the reach of imagination. In the world of big data, the size of data cannot be imagined. Let alone imagine, the growth is almost incomprehensible. A complete restart would mean wasting precious resources, be it time, or CPU capacity. Such a restart in a real-time scenario would also be unpredictable. After all, how do you recover data that changed by the second (or even less) accurately?
Fault tolerance is not just a need, it is an absolute necessity. The lack of a fault tolerance mechanism affects SLAs. A system can be made fault-tolerant by using checkpointing. You can think of a checkpointing mechanism as a recovery process; a system process saves snapshots of application states periodically, and uses these snapshots for recovery in case of failures. A platform developer alone should ensure that a big data platform is checkpoint–compliant. Application developers should only be concerned with their business logic, thus ensuring clear distinction between operability and functional behavior.
Apex treats checkpointing as a native function, allowing application developers to stop worrying about application consistency.
Apache ® Apex does checkpointing intelligently, while relieving application developers of the need to worry about their platforms being failsafe. By transparently checkpointing the state of operators to HDFS periodically, Apex ensures that the operators are recoverable on any node within a cluster. The Apex infrastructure is designed to scale, while ensuring easy recovery at any point during failure. The Apex checkpointing mechanism uses the DFS interface. thereby being agnostic to the DFS implementation.
Apex introduces checkpointing by maintaining operator states within HDFS.
Apex serializes the state of operators to local disks, and then asynchronously copies serialized state to HDFS. The state is asynchronously copied to HDFS in order to ensure that the performance of applications is not affected by the HDFS latency. An operator is considered “checkpointed” only after the serialized state is copied to HDFS. In case of Exactly-Once recovery mechanism, platform checkpoints at every window boundary and it behaves in synchronous mode i.e the operator is blocked till the state is copied to HDFS.
Although Apex is designed to checkpoint at window boundaries, developers can control how optimal a checkpoint operation is. Developers can control how often checkpointing is triggered. They can do this by configuring the window boundary at which checkpointing will occur, by using the CHECKPOINT_WINDOW_COUNT attribute. Frequent checkpoints hamper the overall application performance. This is in stark contrast to sparsely placed checkpoints, which are dangerous because they might make application recovery a time-consuming task.
See this example to see how the apex checkpointing mechanism works.
In our example, let us set CHECKPOINT_WINDOW_COUNT to 1. This diagram shows the flow of data within window boundaries. You will see that at the end of each window, Apex checkpoints data in order to ensure that it is consistent. If the operator crashes during window n+1, Apex restores it to nearest stable state, in this example, the state obtained by introducing checkpointing at the end of window n. The operator now starts processing window n+1 from the beginning. If CHECKPOINT_WINDOW_COUNT was set to 2, then there would have been one checkpoint before window n, and another checkpoint after window n+1.
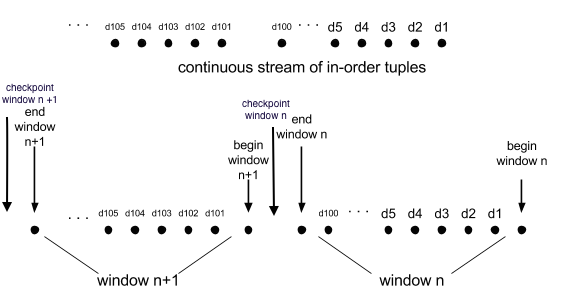
Judicious checkpointing ensures optimum application performance
Checkpointing is a costly and a resource-intensive operation, indicating that an overindulgence will impact an application’s performance. To act as a deterrent to the performance slowdown because of checkpointing, Apex checkpoints non-transient data only. For example, in JDBC operator, connection can be reinitialized at the time of setup, it should be marked as transient, and thus omitted from getting checkpointed.
Application developers must know whether to checkpoint or not; the thumb rule dictates that operators for which computation depends on the previous state must be checkpointed. An example is the Counter operator, which tracks the number of tuples processed by the system. Because the operator relies on its previous state to proceed, it needs to be checkpointed. Some operators are stateless; their computation does not depend on the previous state. Application developers can omit such operators from checkpointing operations by using the STATELESS attribute or by annotating the operator with Stateless.
DataTorrent helps our customers get into production quickly using open source technologies to handle real-time, data-in-motion, fast, big data for critical business outcomes. Using the best-of-breed solutions in open source, we harden the open source applications to make them act and look as one through our unique IP that we call Apoxi™. Apoxi is a framework that gives you the power to manage those open source applications reliably just like you do with your proprietary enterprise software applications, lowering the time to value (TTV) with total lower cost of ownership (TCO). To get started, you can download DataTorrent RTS or micro data services from the DataTorrent AppFactory.
[…] be able to recover the state of an operator, it needs to be saved or checkpointed. In Apex, this is done through a pluggable mechanism which by default serializes the operator state […]